图分析引擎¶
GraphScope 的图分析引擎继承了 GRAPE , 该系统于 SIGMOD2017 上首次提出并获得最佳论文奖。
与以往的系统的不同,GRAPE 支持将串行图算法自动并行化。在 GRAPE 中, 只需进行很小的更改即可轻松地将串行算法即插即用,使其并行化的运行在分布式环境,并高效地处理大规模图数据。 除了易于编程外,GRAPE 还被设计为高效且可拓展的系统,可灵活应对现实中图应用多变的规模、多样性和复杂性。
内置算法¶
GraphScope 图分析引擎内置了许多常用的图分析算法,包括连通性分析算法、路径分析算法、社区检测和中心度计算等类型。
内置算法可以在图上轻松调用。例如,
import graphscope
from graphscope.dataset import load_p2p_network
# 创建默认 session,并加载属性图
g = load_p2p_network()
# 大多数内置算法只支持在简单图上进行计算,因此我们需要先通过顶点和边的类型来生成一个简单图
simple_g = g.project(vertices={"host": ["id"]}, edges={"connect": ["dist"]})
result_lpa = graphscope.lpa(simple_g, max_round=20)
result_sssp = graphscope.sssp(simple_g, src=20)
内置算法的完整列表如下所示。具体某个算法是否支持属性图也在其文档进行了描述。
算法的支持列表会随着不断增加持续更新中。
对计算结果的处理¶
当完成一次图计算,计算结果会被包装成 Context 类,保存在分布式集群的内存中。
用户可能希望将结果传到客户端进行处理,或是写入云中某位置或分布式文件系统。GraphScope 支持用户通过以下方法来获取结果数据。
# 转化为相应数据类型
result_lpa.to_numpy("r")
result_lpa.to_dataframe({"node": "v.id", "result": "r"})
# 或写入 hdfs、oss, 或本地目录中(pod中的本地目录)
result_lpa.output("hdfs://output", {"node": "v.id", "result": "r"})
result_lpa.output("oss://id:key@endpoint/bucket/object", {"node": "v.id", "result": "r"})
result_lpa.output("file:///tmp/path", {"node": "v.id", "result": "r"})
# 或写入本地的 client 中
result_lpa.output_to_client("/tmp/lpa_result.txt", {"node": "v.id", "result": "r"})
# 或写入 vineyard 数据结构
result_lpa.to_vineyard_dataframe({"node": "v.id", "result": "r"})
result_lpa.to_vineyard_tensor("r")
此外,如 快速上手 中所示,用户可以将计算结果加回到该图数据中作为顶点(边)的新属性(列)。
# 将结果作为新列添加回属性图,列名为 "lpa_result",并生成一张新图
new_graph = g.add_column(result_lpa, {"lpa_result": "r"})
用户可以通过选择器( Selector )来定义将计算结果中的哪些部分写回图数据。
选择器指定了计算结果中的哪一部分会被处理。类似的,图数据也可以作为被处理数据的一部分,例如顶点ID。
我们为选择器保留了三个关键字:r 代表结果,v 和 e 分别代表顶点和边。
以下是结果处理中选择器的一些示例。
# 获取顶点上的结果
result_lpa.to_numpy('r')
# 转换为 dataframe,
# 使用顶点的 `id` 作为名为 df_v 的列
# 使用顶点的 `data` 作为名为 df_vd 的列
# 使用结果列作为名为 df_result 的列
result_lpa.to_dataframe({'df_v': 'v.id', 'df_vd': 'v.data', 'df_result': 'r'})
# using the property0 written on vertices with label0 as column `result`
# 对于属性图的结果
# 使用 `:` 作为v和e的标签选择器
# 将 label0 顶点的 id (`v:label0.id`)作为 `id` 列
# 使用写在带有label0的顶点上的property0作为`result`列
result.output(fd='hdfs:///gs_data/output', \
selector={'id': 'v:label0.id', 'result': 'r:label0.property0'})
使用 PIE 编程模型自定义算法¶
如果内置算法无法满足需求,用户可以编写自己的算法。用户可以通过 graphscope 在纯 Python 模式
下使用 PIE 编程模型编写算法。
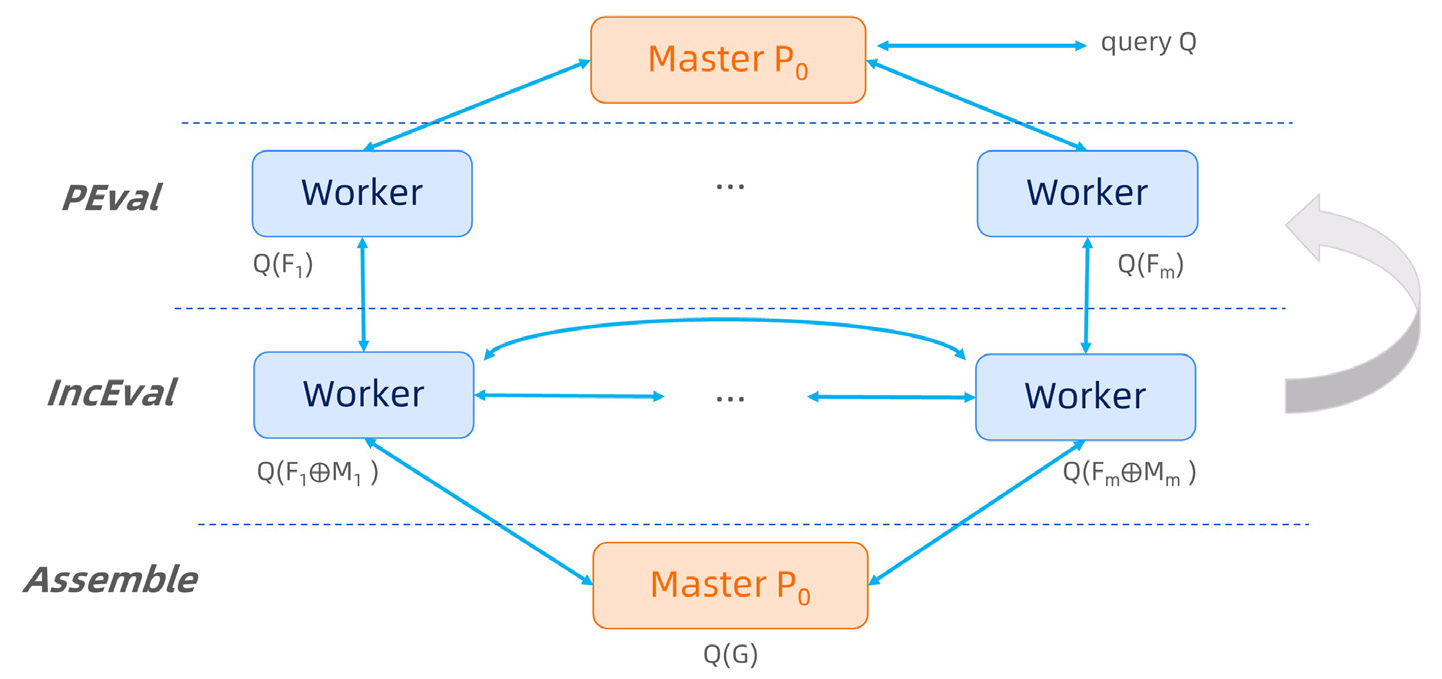
为了实现自己的算法,用户需要实现此类。
from graphscope.analytical.udf.decorators import pie
from graphscope.framework.app import AppAssets
@pie(vd_type="double", md_type="double")
class YourAlgorithm(AppAssets):
@staticmethod
def Init(frag, context):
pass
@staticmethod
def PEval(frag, context):
pass
@staticmethod
def IncEval(frag, context):
pass
如代码所示,用户需要实现一个以 @pie 装饰的类,并提供三个串行
图算法函数。其中,Initialize 函数用于设置算法初始状态,PEval 函数定义算法的局部计算,
IncEval 函数定义对分区数据的增量计算。与 fragment 相关的完整 API 可以参考 Cython SDK API.
以单源最短路径算法 SSSP 为例,用户在 PIE 模型中定义的 SSSP 算法可如下所示。
from graphscope.analytical.udf.decorators import pie
from graphscope.framework.app import AppAssets
@pie(vd_type="double", md_type="double")
class SSSP_PIE(AppAssets):
@staticmethod
def Init(frag, context):
v_label_num = frag.vertex_label_num()
for v_label_id in range(v_label_num):
nodes = frag.nodes(v_label_id)
# 初始化每个顶点的距离
context.init_value(
nodes, v_label_id, 1000000000.0, PIEAggregateType.kMinAggregate
)
context.register_sync_buffer(v_label_id, MessageStrategy.kSyncOnOuterVertex)
@staticmethod
def PEval(frag, context):
# 从context中获取源顶点
src = int(context.get_config(b"src"))
graphscope.declare(graphscope.Vertex, source)
native_source = False
v_label_num = frag.vertex_label_num()
for v_label_id in range(v_label_num):
if frag.get_inner_node(v_label_id, src, source):
native_source = True
break
if native_source:
context.set_node_value(source, 0)
else:
return
e_label_num = frag.edge_label_num()
# 在源顶点所在分区中,运行dijkstra算法作为部分计算
for e_label_id in range(e_label_num):
edges = frag.get_outgoing_edges(source, e_label_id)
for e in edges:
dst = e.neighbor()
# 使用边上第三列数据作为两点之间的距离
distv = e.get_int(2)
if context.get_node_value(dst) > distv:
context.set_node_value(dst, distv)
@staticmethod
def IncEval(frag, context):
v_label_num = frag.vertex_label_num()
e_label_num = frag.edge_label_num()
# 增量计算,更新最短距离
for v_label_id in range(v_label_num):
iv = frag.inner_nodes(v_label_id)
for v in iv:
v_dist = context.get_node_value(v)
for e_label_id in range(e_label_num):
es = frag.get_outgoing_edges(v, e_label_id)
for e in es:
u = e.neighbor()
u_dist = v_dist + e.get_int(2)
if context.get_node_value(u) > u_dist:
context.set_node_value(u, u_dist)
如代码所示,用户仅需要设计和实现单分区的串行算法,而不需要考虑分布式环境中的分区通信和消息传递。 在这种情况下,经典的 Dijkstra 算法及其增量版本就可以用于在集群上的大规模图数据计算。
使用 Pregel 编程模型自定义算法¶
除了基于子图的 PIE 模型之外,graphscope 也支持以顶点为中心的 Pregel 编程模型。
您可以通过实现以下算法类来在 Pregel 模型中开发算法。
from graphscope.analytical.udf.decorators import pregel
from graphscope.framework.app import AppAssets
@pregel(vd_type='double', md_type='double')
class YourPregelAlgorithm(AppAssets):
@staticmethod
def Init(v, context):
pass
@staticmethod
def Compute(messages, v, context):
pass
@staticmethod
def Combine(messages):
pass
与 PIE 模型不同,Pregel 算法类的装饰器为 @pregel ,该类方法是
定义在顶点上的,而不同于 PIE 模型中定义在图分区上。
还是以 SSSP 为例,Pregel 模型下的算法如下所示。
# 装饰器, 定义顶点数据和消息数据的类型
@pregel(vd_type="double", md_type="double")
class SSSP_Pregel(AppAssets):
@staticmethod
def Init(v, context):
v.set_value(1000000000.0)
@staticmethod
def Compute(messages, v, context):
src_id = context.get_config(b"src")
cur_dist = v.value()
new_dist = 1000000000.0
if v.id() == src_id:
new_dist = 0
for message in messages:
new_dist = min(message, new_dist)
if new_dist < cur_dist:
v.set_value(new_dist)
for e_label_id in range(context.edge_label_num()):
edges = v.outgoing_edges(e_label_id)
for e in edges:
v.send(e.vertex(), new_dist + e.get_int(2))
v.vote_to_halt()
@staticmethod
def Combine(messages):
ret = 1000000000.0
for m in messages:
ret = min(ret, m)
return ret
自定义算法中使用 math.h 中的函数¶
GraphScope 支持用户在自定义算法中通过 context.math 上的接口来使用定义在 math.h 中的 C 函数,
例如,下列代码,
@staticmethod
def Init(v, context):
v.set_value(context.math.sin(1000000000.0 * context.math.M_PI))
会被翻译成如下的 C 代码以高效地执行,
... Init(...)
v.set_value(sin(1000000000.0 * M_PI));
运行自定义算法¶
运行自定义算法,用户需要在定义算法后调用算法。
import graphscope
from graphscope.dataset import load_p2p_network
g = load_p2p_network(generate_eid=False)
# 加载自己的算法
my_app = SSSP_Pregel()
# 在图上运行自己的算法,得到计算结果
# 这里 `src` 是与 `context.get_config(b"src")` 相对应的
ret = my_app(g, src="6")
在开发和测试之后,您可以通过 to_gar 方法将算法保存成 gar 包以备将来使用。
SSSP_Pregel.to_gar("/tmp/my_sssp_pregel.gar")
在此之后,您可以从 gar 包加载自定义的算法。
from graphscope.framework.app import load_app
# 从gar包中加载自己的算法
my_app = load_app("/tmp/my_sssp_pregel.gar")
# 在图上运行自己的算法,得到计算结果
ret = my_app(g, src="6")
运行Java编写的算法¶
GraphScope 支持用户编写Java的PIE app,并且运行在图分析引擎上。我们首先通过一个简单的例子来演示如果在GraphScope 图分析引擎上运行一个Java的图算法(bfs),然后我们将展示如果实现并运行自定义的Java图算法。
运行示例的Java算法¶
我们提供了一些经典图分析算法的示例实现,通过下面展示的例子,你可以尝试在GraphScope的图分析引擎上试着运行他们。首先你需要从下载我们提供的示例app的合集 grape-demo.jar <https://github.com/GraphScope/gstest/blob/master/jars/grape-demo-0.17.0-shaded.jar>_,无需任何更改你就可以在 GraphScope图分析引擎上运行这些示例算法。
然后你需要打开GraphScope的python client,尝试载图并且运行一个简单的bfs的算法。
import graphscope
from graphscope import JavaApp
from graphscope.dataset import load_p2p_network
"""Or launch session in k8s cluster"""
sess = graphscope.session(cluster_type='hosts')
graph = load_p2p_network(sess)
"""This app need to run on simple graph"""
graph = graph.project(vertices={"host": ['id']}, edges={"connect": ["dist"]})
sssp=JavaApp(
full_jar_path="grape-demo.jar", # The path to the grape-demo.jar
java_app_class="com.alibaba.graphscope.example.bfs.BFS",
)
ctx=sssp(graph,src=6)
"""Fetch the result via context"""
ctx.to_numpy("r:label0.dist_0")
使用Java编写用户自定义的图算法¶
为了编写Java实现的图算法,用户需要借助于 grape-jdk。请参考 About Grape JDK 来将 grape-jdk 安装到你的本地环境上。
安装完成后,你需要将 grape-jdk 的依赖添加到你的maven项目依赖中。用户应当注意在 grape-jdk 的依赖配置上应当添加 classifier shaded ,来确保
所有必要的依赖都被包括到。
<dependency>
<groupId>com.alibaba.graphscope</groupId>
<artifactId>grape-jdk</artifactId>
<version>0.1</version>
<classifier>shaded</classifier>
</dependency>
用户在开发自己算法的过程中,可能会用到其他的第三方jar包。为了解决依赖jar包的版本问题,用户需要使用确保自己生成的jar包包含所有依赖的jar包。 例如,用户可以使用maven插件 maven-shade-plugin.
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
</plugin>
用户在自定义的图算法时,用户需要按照 PIE 来实现自定义算法,
并且需要根据需要的app类型来实现 grape-jdk 中相应的接口并且实现接口。
如果用户期望算法运行在属性图上,那么定义的app应该实现接口 DefaultPropertyAppBase 或 ParallelPropertyAppBase。
如果用户期望算法运行在简单图上,那么定义的app应该实现借口 DefaultAppBase 或 ParallelAppBase
同时用户需要实现app相应的 context,来保存跨SuperStep的数据,其应该是 DefaultPropertyContextBase , ParallelPropertyContextBase,
DefaultContextBase 或者 ParallelContextBase 的的子类。通过继承 VertexDataContext 或者 VertexPropertyContext
用户可以使用到不同类型的context所拥有的特性。通过这两种context提供的借口所存储的数据在程序执行完之后可以被用户访问,用户可以通过在python client中query返回的context
对象来访问这些数据。
这里我们展示一个简单的app的实现,它所做的事情只是对一个简单图的所有边进行了遍历。
public class Traverse implements ParallelAppBase<Long, Long, Double, Long, TraverseContext>,
ParallelEngine {
@Override
public void PEval(IFragment<Long, Long, Double, Long> fragment,
ParallelContextBase<Long, Long, Double, Long> context,
ParallelMessageManager messageManager) {
TraverseContext ctx = (TraverseContext) context;
for (Vertex<Long> vertex : fragment.innerVertices()) {
AdjList<Long, Long> adjList = fragment.getOutgoingAdjList(vertex);
for (Nbr<Long, Long> nbr : adjList.iterator()) {
Vertex<Long> dst = nbr.neighbor();
//Update largest distance for current vertex
ctx.vertexArray.setValue(vertex, Math.max(nbr.data(), ctx.vertexArray.get(vertex)));
}
}
messageManager.ForceContinue();
}
@Override
public void IncEval(IFragment<Long, Long, Double, Long> fragment,
ParallelContextBase<Long, Long, Double, Long> context,
ParallelMessageManager messageManager) {
TraverseContext ctx = (TraverseContext) context;
for (Vertex<Long> vertex : fragment.innerVertices()) {
AdjList<Long, Long> adjList = fragment.getOutgoingAdjList(vertex);
for (Nbr<Long, Long> nbr : adjList.iterator()) {
Vertex<Long> dst = nbr.neighbor();
//Update largest distance for current vertex
ctx.vertexArray.setValue(vertex, Math.max(nbr.data(), ctx.vertexArray.get(vertex)));
}
}
}
}
该app对应的context的实现:
public class TraverseContext extends
VertexDataContext<IFragment<Long, Long, Double, Long>, Long> implements ParallelContextBase<Long,Long,Double,Long> {
public GSVertexArray<Long> vertexArray;
public int maxIteration;
@Override
public void Init(IFragment<Long, Long, Double, Long> frag,
ParallelMessageManager messageManager, JSONObject jsonObject) {
createFFIContext(frag, Long.class, false);
//This vertex Array is created by our framework. Data stored in this array will be available
//after execution, you can receive them by invoking method provided in Python Context.
vertexArray = data();
maxIteration = 10;
if (jsonObject.containsKey("maxIteration")){
maxIteration = jsonObject.getInteger("maxIteration");
}
}
@Override
public void Output(IFragment<Long, Long, Double, Long> frag) {
//You can also write output logic in this function.
}
}
在实现了自己的算法之后,用户可能会想在提交到GraphScope的图分析引擎运行前,先在本地验证算法实现的正确性。我们提供了一个简单的脚本来满足用户的 这个需求。为了验证算法实现的正确性,用户只需要运行以下命令:
python3 ${GRAPHSCOPE_REPO}/analytical_engine/java/java-app-runner.py
--app=${app_class_name} --java_path=${path_to_your_jar}
--param_str=${params_str}
其中, app_class_name 是用户自定义的Java app的类的全名,(i.e. com.xxx.Traverse), path_to_your_jar 指向包含用户想要运行的算法的jar包。
可以通过 param_str 来制定context初始化需要的参数,例如对于bfs算法可以使用 src=6,threadNum=1 来标记初始节点是6,并行线程数为1。例如,可以
通过如下命令来运行Traverse app。
cd ${GRAPHSCOPE_REPO}/analytical_engine/java/
python3 java-app-runner.py --app com.alibaba.graphscope.example.traverse.Traverse
--jar_path /home/graphscope/GraphScope/analytical_engine/java/grape-demo/target/grape-demo-0.17.0-shaded.jar
--arguments "maxIteration=10"
在本地验证自定义算法的正确性之后,你可以通过GraphScope的python client来提交运行jar包。一个jar包中可以包含不同的app实现,用户可以多次提交相同的jar包但是运行不同 的app。
import graphscope
from graphscope import JavaApp
from graphscope.dataset import load_p2p_network
"""Or launch session in k8s cluster"""
sess = graphscope.session(cluster_type='hosts')
graph = load_p2p_network(sess)
graph = graph.project(vertices={"host": ['id']}, edges={"connect": ["dist"]})
app=JavaApp(
full_jar_path="{full/path/to/your/packed/jar}",
java_app_class="{fully/qualified/class/name/of/your/app}",
)
ctx=app(graph, "${param string}")
请耐心等待计算完成,当计算完成后,你可以通过 Context 对象来获取计算结果。
相关论文
Wenfei Fan, Jingbo Xu, Wenyuan Yu, Jingren Zhou, Xiaojian Luo, Ping Lu, Qiang Yin, Yang Cao, and Ruiqi Xu. Parallelizing Sequential Graph Computations., ACM Transactions on Database Systems (TODS) 43(4): 18:1-18:39.
Wenfei Fan, Jingbo Xu, Yinghui Wu, Wenyuan Yu, Jiaxin Jiang. GRAPE: Parallelizing Sequential Graph Computations., The 43rd International Conference on Very Large Data Bases (VLDB), demo, 2017 (the Best Demo Award).
Wenfei Fan, Jingbo Xu, Yinghui Wu, Wenyuan Yu, Jiaxin Jiang, Zeyu Zheng, Bohan Zhang, Yang Cao, and Chao Tian. Parallelizing Sequential Graph Computations., ACM SIG Conference on Management of Data (SIGMOD), 2017 (the Best Paper Award).