Introducing GAIA: A Scalable Engine for Gremlin – the SQL for Graphs
 GAIA extends GraphScope with Gremlin, the industry’s de facto standard property graph query language defined and maintained by the Apache TinkerPop project, which is widely adopted by popular graph database vendors such as Neo4j, OrientDB, JanusGraph, Microsoft Cosmos DB, and Amazon Neptune. GAIA is the first open-source implementation of Gremlin in a distributed or big-data environment in the industry.
GAIA extends GraphScope with Gremlin, the industry’s de facto standard property graph query language defined and maintained by the Apache TinkerPop project, which is widely adopted by popular graph database vendors such as Neo4j, OrientDB, JanusGraph, Microsoft Cosmos DB, and Amazon Neptune. GAIA is the first open-source implementation of Gremlin in a distributed or big-data environment in the industry.
Making Gremlin Accessible to Data Scientists: Historical Background
Since about two years ago, we have heard an increasing demand from data scientists at Alibaba to extract insights from structural patterns on massive heterogeneous datasets in a wide variety of important application domains such as e-commerce, on-line payments, and social media. Such data is naturally modeled as graphs to encode complex interrelationships among entities.
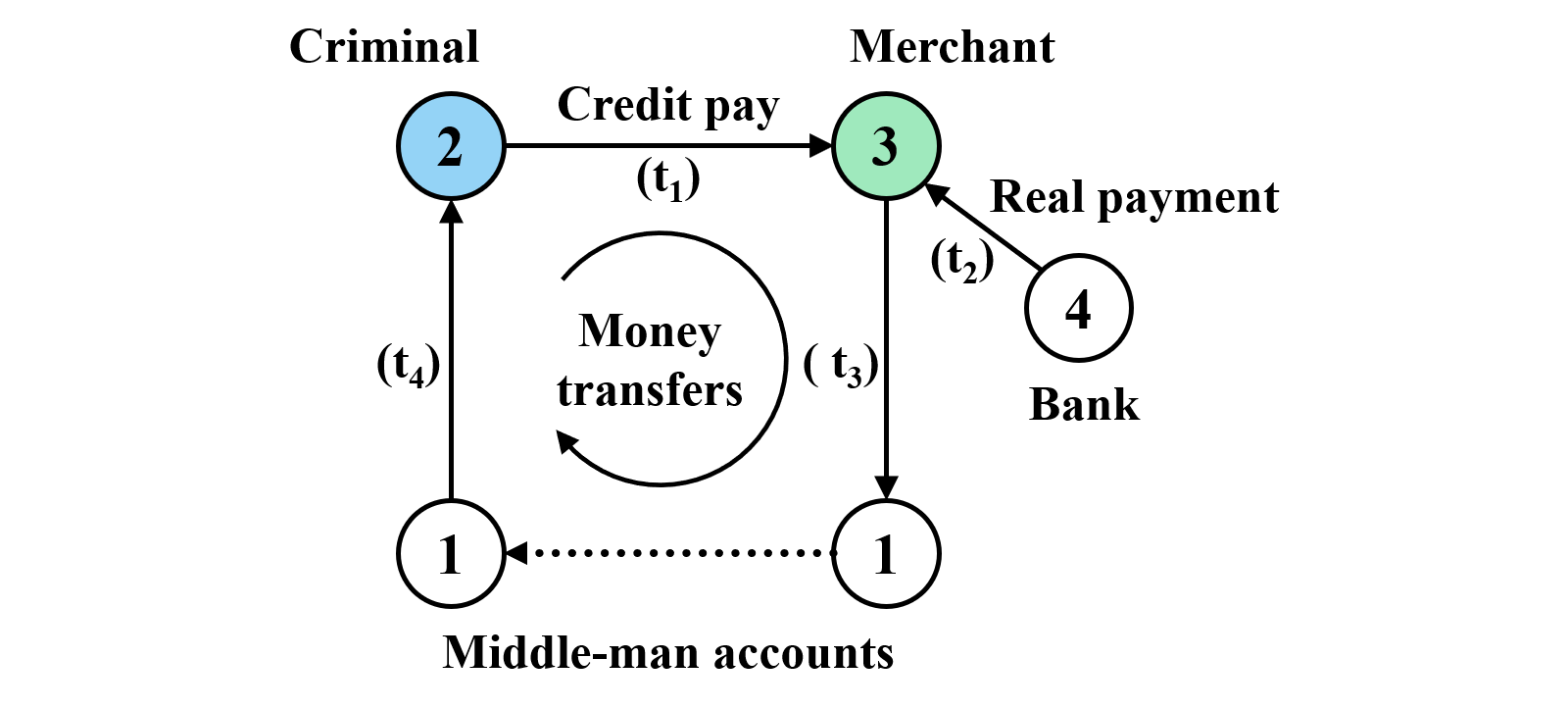
As an example, consider the graph depicted in the above figure. It is a simplified subgraph pattern of the one employed at Alibaba for credit-card fraud detection [2,3]. By using a fake identifier, the “criminal” may obtain a short-term credit from a bank (vertex 4). He/she tries to illegally cash out money by forging a purchase (edge 2–>3) at time t1 with the help of a merchant (vertex 3). Once receiving payment (edge 4–>3) from the bank (vertex 4), the merchant tries to send the money back (edges 3–>1 and 1–>2) to the “criminal” via multiple accounts of a middle man (vertex 1) at time t3 and t4, respectively. This pattern eventually forms a cycle (2–>3–>1…–>2).
In practice, the graph can contain billions of vertices (e.g., users) and hundreds of billions to trillions of edges (e.g., payments), and the entire fraudulent process can involve much more complex chains of transactions, through many entities, with various constraints, which therefore requires complex interactive analysis to identify. Although many distributed and parallel graph processing frameworks exist, writing efficient distributed algorithms for each particular task is exceedingly hard [4], especially for our target users of domain experts or data scientists.
Motivated by the above (and many other) use cases, we started the GAIA project to offer a new distributed infrastructure for this new class of graph applications. GAIA differs from prior systems in two important ways: by exploiting Gremlin to provide a high-level language for graph and/or pattern traversal, and by supporting automatic parallel execution with advanced optimizations such as hybrid (BFS/DFS) traversal for bounded-memory execution and early stop (to avoid wasted computation).
Scaling Gremlin for Large Distributed Graphs: A Closer Look
Gremlin offers a flexible and expressive programming model to enable non-technical users to succinctly express complex traversal patterns in real-world applications. For example, one can write the above fraud-detection query in just a couple of lines using Gremlin, as shown below. In contrast, even common operations like cycle detection, which is a core part of the fraud-detection use case, is tricky to implement in existing graph systems.
g.V('account').has('id','2').as('s')
.repeat(out('transfer').simplePath())
.times(k-1)
.where(out('transfer').as('s'))
.path().limit(1)
- The query finds cyclic paths of length
k, starting from a given account. First, the source operatorV(with thehasfilter) returns all theaccountvertices with an identifier of “2”. Theasoperator is a modulator that introduces a tag (sin this case) for later references. Second, it traverses the outgoingtransferedges for exactlyk-1times, skipping any repeated vertices (by thesimplePathoperator). Third, thewhereoperator checks if the starting vertexscan be reached by one more step, that is, whether a cycle of lengthkis formed. Finally, for qualifying traversers, thepathoperator returns the full path information. Thelimitoperator at the end indicates only one such result is needed.
GAIA is designed to faithfully preserve the programming model of Gremlin. As a result, it can be used to scale existing Gremlin applications to large compute clusters with no (or minimum) modification. GAIA achieves high performance for complex Gremlin traversal by compiling it into a dataflow that can be executed efficiently in a distributed system deployed on large clusters. We refer interested readers to this paper [1] for the full technical details of GAIA.
The following figure shows a comparison between GAIA and JanusGraph using the LDBC Social Network Benchmark (Interactive Workload). JanusGraph cannot process query in parallel, and we run GAIA in one machine for fair comparison. We run each query on GAIA with the degree of parallelism varying from 1 to 16, and report its max and min latency for each query while compared to JanusGraph.
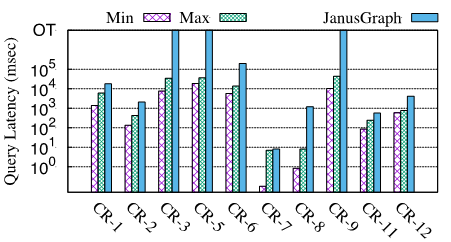
JanusGraph fails to answer many queries (CR-3,5,9) due to out-of-time (OT). As shown, even the maximum latency (single-thread) of GAIA is much shorter than that of JanusGraph in all cases. In addition, GAIA can scale those large, complex traversal queries almost linearly across multiple servers [1].
Conclusion
We’ve been building GAIA at Alibaba for over a year now and it is still under very active development. Find the current pre-release on GitHub here. Meanwhile, we are working on integrating GAIA into the GraphScope project to make the “SQL for Graphs” available for a wider community of users to work with big data or data science. An early alpha release of GAIA will be included in GraphScope coming this summer, and we will further develop and refine GAIA to ship more Gremlin features such as the match-step for declarative pattern queries and iterative graph algorithms via the subgraph-step, both tentatively scheduled for release in late 2021.
Graph technology is changing AI [5]. We’re excited to be creating new tools and fostering innovative graph solutions in the amazing community. We look forward to your feedbacks and contributions.
References
-
[1] Zhengping Qian, Chenqiang Min, Longbin Lai, Yong Fang, Gaofeng Li, Youyang Yao, Bingqing Lyu, Zhimin Chen, Jingren Zhou. GraphScope: A System for Interactive Analysis on Distributed Graphs Using a High-Level Language. (pdf)
-
[2] Bingqing Lyu, Lu Qin, Xuemin Lin, Ying Zhang, Zhengping Qian, and Jingren Zhou. Maximum biclique search at billion scale. Awarded Best Paper Runner-up in VLDB 2020. (pdf)
-
[3] Xiafei Qiu, Wubin Cen, Zhengping Qian, You Peng, Ying Zhang, Xuemin Lin, and Jingren Zhou. Real-time constrained cycle detection in large dynamic graphs. In VLDB 2018. (pdf)
-
[4] Vasiliki Kalavri, Vladimir Vlassov, Seif Haridi. High-Level Programming Abstractions for Distributed Graph Processing. (pdf)
-
[5] Robert H.P. Engels. The Rise of Graph Technology. https://www.linkedin.com/pulse/rise-graph-technology-robert-h-p-engels-/