Towards a Swiss Army Knife for a Continuous Life Cycle of Big Graph Analytics
 In this post, we will present a high-level road-map of the GraphScope project with highlighting new exciting features coming in the v0.5 release.
In this post, we will present a high-level road-map of the GraphScope project with highlighting new exciting features coming in the v0.5 release.
How It All Gets Started
To begin with, let us reflect on why we start this project. Due to huge diversity of graph data, scenarios, and algorithms, agility is key to the success of a big graph infrastructure, which boils down firstly to the ease of programming and interoperability. GraphScope generalizes previous execution environments such as Giraph and GraphX in two ways: by providing a single-machine programming abstraction in Python that supports familiar notations for a variety of graph operations (Gremlin, NetworkX, Graph Neural Networks, etc.) while hiding the system complexity from the programmer; and by bridging with other, existing big data infrastructure through Vineyard which provides efficient in-memory data transfer with high-level data structures as interface, as shown in Figure 1.
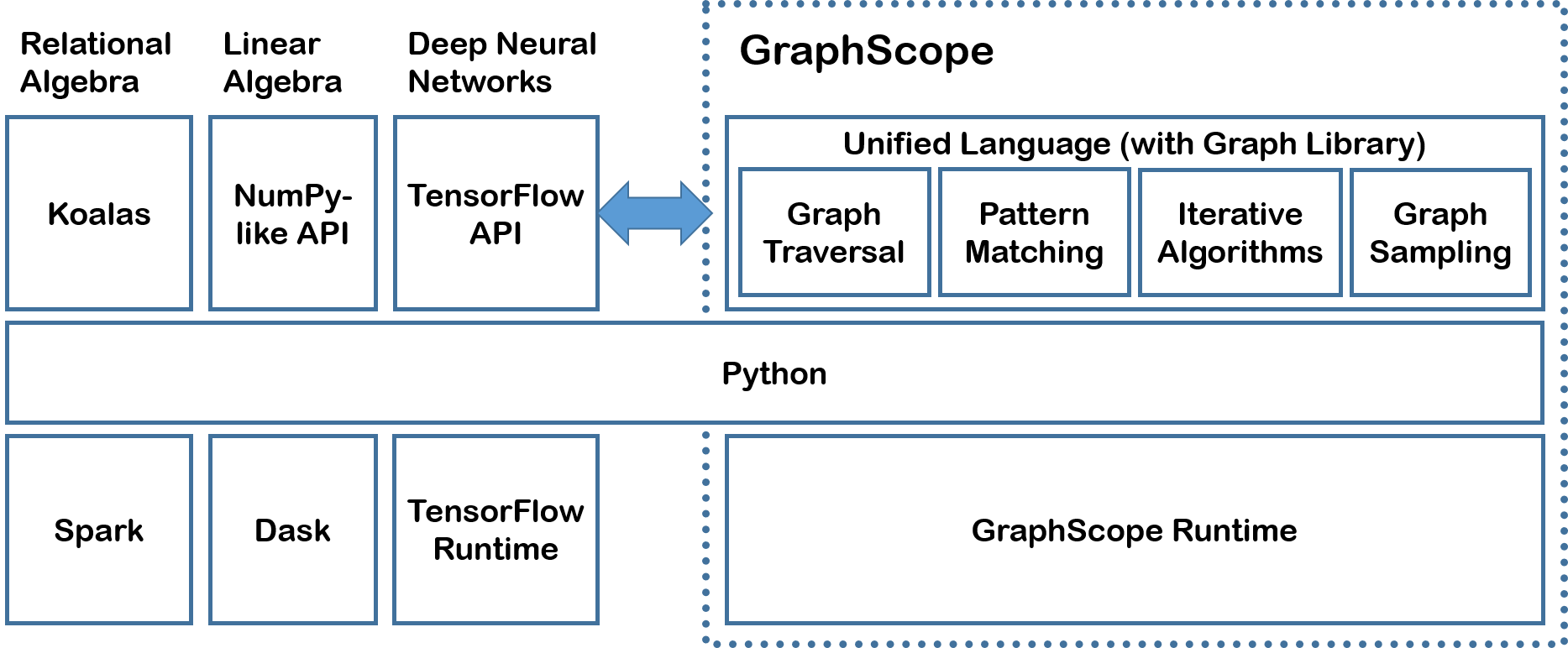
- Figure 1: The GraphScope system stack, and how it interacts with the PyData ecosystem.
A Vision on Big Graph Infrastructure
In addition, we believe big graph infrastructure must be developed for a continuous life cycle. As illustrated in Figure 2, the centered box of “interactive analysis and testing” represents the current version of GraphScope, which facilitates the design of new (or specific) graph algorithms for each particular task in an exploratory manner. As such a process is highly experimental in nature, GraphScope makes it easy to construct and load large graphs on demand and to efficiently perform a wide range of graph computations.
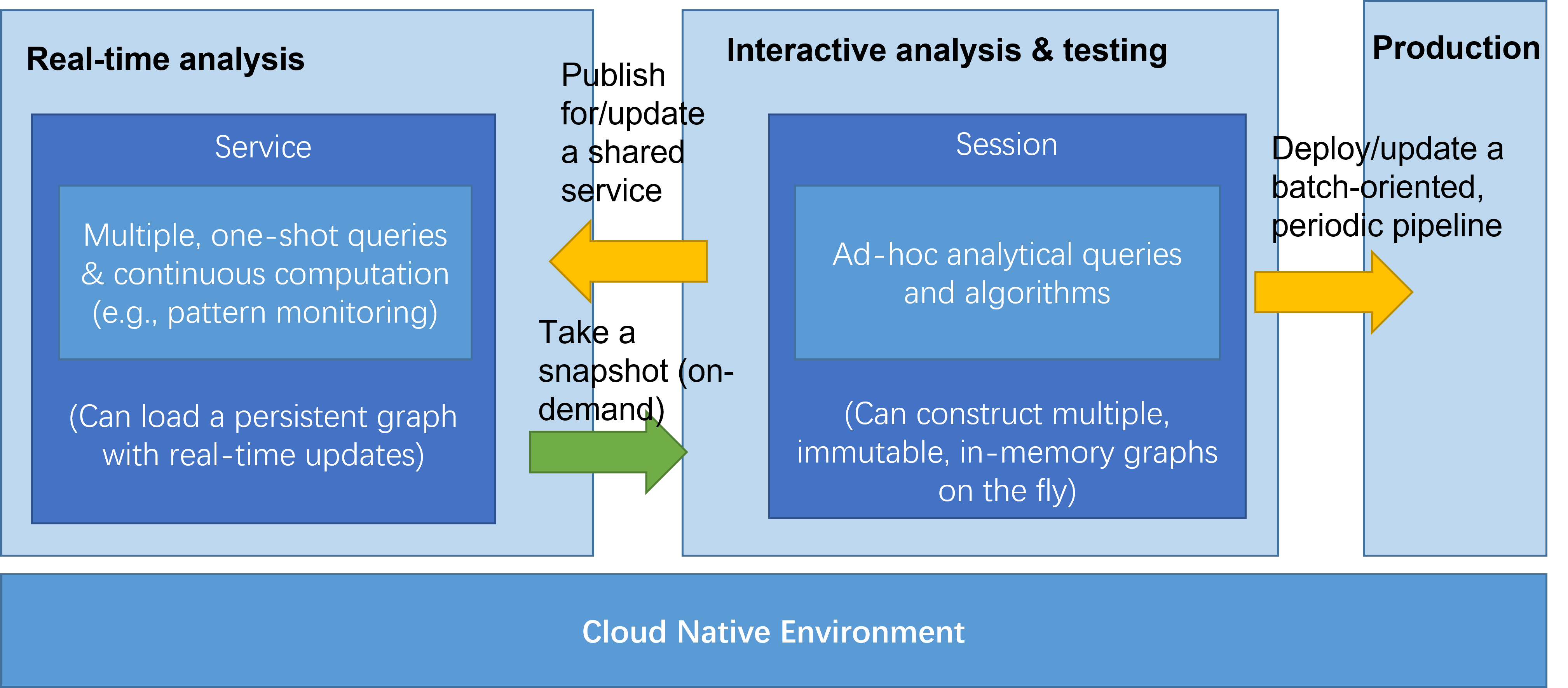
- Figure 2: A continuous life cycle of big graph analytics.
Once such a design is achieved and selected, it will typically be deployed in production for processing real dynamic graphs to generate insights in a continuous manner. The left and right box in Figure 2 show two representative processing paradigms for such a deployment: the real-time streaming and the batch-oriented processing, respectively, at two ends of the latency spectrum. In the real-time streaming, ideally, each update to the graph model has to be reflected in the output within a couple of seconds, and therefore the system optimizes for low latency and high availability. In the batch-oriented processing where the latency requirement is much relaxed, it is often more efficient to perform computation periodically (such as every one hour or day) to allow sophisticated optimizations for throughput.
GraphScope v0.5
As the first step towards the ease of deployment in production, we are introducing two new features in the coming release of GraphScope v0.5, including a persistent graph store to enable a “service mode” for real-time graph computation, and lazy evaluation of GraphScope programs–an execution strategy which delays the execution of a GraphScope program until later when needed for efficiency. We briefly introduce them below and will provide more details in the Release Note soon.
Persistent Graph Store
In addition to Vineyard, the in-memory columnar graph store currently supported in GraphScope, we will introduce a new disk-based row-oriented multi-versioned persistent graph store. While Vineyard focuses on great support for in-memory whole graph analytics workload, the new persistent graph store is geared towards better supporting for running continuous graph data management service that frequently updates the graph and answers traversal queries.
The store is a distributed graph store built on top of the popular RocksDB key value store. It adopts row-oriented design to support frequent small updates to the graph. Each row is tagged with a snapshot ID as its version. A query reads most recent version of rows relative to the snapshot ID when it starts and hence not blocked by writes. For writes we take a compromise between consistency and higher throughput (in a similar design to Kineograph [1]). In our design writes in the same session can be grouped and executed atomically as a unit and the persistent store assigns a snapshot ID (which is a low-resolution timestamp of current time) to each group and executes groups of writes by the order of their snapshot IDs and by a deterministic (though arbitrary) order for groups of writes that occur in the same snapshot ID. It provides high write throughput while still with some degree of order and isolation though it provides less consistency than strict snapshot isolation common in database. We hope our design choice provides an interesting trade-off for practical usage.
Initially, the new persistent store is provided as a separate option from Vineyard. Going foward we hope to evole them into an integrated hybrid graph store suitable for all kinds of workloads.
Lazy Evaluation
As an important performance optimization technique, lazy evaluation has been widely applied by many big data processing systems like TensorFlow. We will introduce the support of lazy evaluation into the coming GraphScope v0.5, which provides three-fold benefits compared with eager evaluation. First, in the lazy evaluation, a job is expressed logically in a directed acyclic graph (DAG) where different nodes represent different operators of the overall job and edges represent the data dependencies between operators. When evaluating the operator (i.e., a vertex in the DAG), GraphScope looks back to check all the nodes that are required for this requested node. Only those nodes are evaluated in the appropriate order. Thus, a node in the DAG is evaluated only when needed; only if it is needed. Second, with the DAG in place, it can avoid repeatedly evaluating the same operator, blindly, regardless whether the operator can be memorized. Third, it allows to combine multiple operators (e.g., adding an edge to a graph) into a single batch-oriented operator (e.g., aggregating multiple edges into a batch and adding the batch to a graph), which is more efficient in GraphScope.
In GraphScope, developers can easily switch between lazy-mode and eager-mode by just setting the value of mode as lazy or eager when creating a session graphscope.session(mode='lazy'or 'eager'). Typically, developers can choose the eager-mode in the development stage, as it can ease the debugging of applications, while switch to the lazy-mode in the deployment stage for better performance.
Conclusion
A tool or infrastructure built for a continuous life cycle of big graph applications requires to do much more than the ease of deployment, but also to help testing and diagnosis of real-world graph applications, and to allow a data-driven approach for continuous evolution of an on-line service or periodic pipeline. Even so, the new features coming in the GraphScope v0.5 release take us one step closer to that vision. Please give it a try and let us know what you think! Really appreciated.
References
[1] Raymond Cheng, Ji Hong, Aapo Kyrola, Youshan Miao, Xuetian Weng, Ming Wu, Fan Yang, Lidong Zhou, Feng Zhao, and Enhong Chen. 2012. Kineograph: Taking the Pulse of A Fast-changing and Connected World. In EuroSys ‘12. (pdf)