Breaking the Language Barrier in Large Scale Graph Computing
 In this blog, we present GRAPE-JDK,
an efficient cross-language graph analysis development kit of GraphScope. GRAPE-JDK enables users to write customized graph algorithms in Java and run them efficiently on GraphScope by addressing various challenges in cross-language graph computation.
In this way, Java algorithms developed based on GRAPE-JDK can achieve performance similar to C++ algorithms.
In this blog, we present GRAPE-JDK,
an efficient cross-language graph analysis development kit of GraphScope. GRAPE-JDK enables users to write customized graph algorithms in Java and run them efficiently on GraphScope by addressing various challenges in cross-language graph computation.
In this way, Java algorithms developed based on GRAPE-JDK can achieve performance similar to C++ algorithms.
The Demand and Challenges of Cross-language Graph Analysis
Graph analytics is a critical aspect of processing tasks involving graphs. One notable example of a graph analysis algorithm is the widely used single-source shortest path (SSSP) algorithm. The graph analytical engine in GraphScope is derived from GRAPE, as documented in the research paper available at GRAPE. This engine incorporates various pre-built graph analysis algorithms, including SSSP and PageRank, among others, which users can readily invoke for their analytical needs.
In real-world production scenarios, customization of general algorithms is often required to accommodate specific business logic. As a result, developers frequently need to develop their own algorithms tailored to their needs. Java is widely adopted as the predominant language within big data ecosystems, making it an ideal choice for implementing these algorithms. However, when utilizing GraphScope’s graph analytical engine, relying solely on the C++ interface can present significant obstacles for developers. Directly implementing algorithms in Java would be more seamless and efficient for them. Therefore, there exists a demand for enabling users to leverage Java for implementing customized graph algorithms and seamlessly executing them on the GraphScope graph analytical engine. This approach would address practical requirements while facilitating a smoother integration of user-developed algorithms into the system.
To meet the user’s requirement for conducting cross-language graph analysis, we have developed a Java SDK that builds upon the graph analysis engine GRAPE, which is primarily implemented in C++. In such scenarios, a natural solution is to employ the Java Native Interface (JNI), which serves as the standard framework for Foreign Function Interface (FFI) on the Java Virtual Machine (JVM). By utilizing JNI, we can overcome the limitations of Java by accessing system hardware resources at a lower level, similar to C++. To leverage JNI effectively, it requires writing wrapper code in C++ and compiling it into a dynamic library, granting us the ability to seamlessly utilize its functionalities. This approach facilitates the seamless integration of Java and C++ components, enabling developers to harness the full potential of both languages within the graph analysis process.
Therefore, we can find a straightforward and intuitive solution: employing the raw JNI to create wrapper code that bridges Java and C++. This approach allows us to encapsulate the C++ interface of the graph computing engine as a Java interface, making it accessible to users. However, this native solution has inherent limitations that render it inadequate for meeting the demands of large-scale graph computing. It confronts several challenges in following three aspects:
Challenge 1: Difficulty in JNI Programming
Directly using JNI for cross-language programming poses challenges in development, debugging, and maintenance.
- Development: In order to enable Java to interact/communicate with C++, programmers need to write a large amount of error-prone and boilerplate code, as shown in the code block. And JNI code often involves pointer conversion, which increases the risk of errors.
JNIEXPORT void JNICALL Java_com_alibaba_graphscope_stdcxx_StdVector_1cxx_10x8cbe72bf_nativeClear(JNIEnv*, jclass, jlong ptr) {
reinterpret_cast<std::vector<gs::VertexArrayDefault<double>>*>(ptr)->clear();
}
-
Debugging: The written JNI code needs to be compiled into a dynamic library by a C++/C compiler for the JVM to load and invoke the functions defined in it. The compilation and debugging of JNI code is also a painful process.
-
Maintenance: The cost of maintaining JNI code is also high. As JNI code is highly dependent on C++ native code, when the C++ interface and implementation of the graph computing engine change, programmers must manually modify the JNI implementation to adapt.
Challenge 2: Huge Overhead of Cross-language Access
Although JNI provides sufficient APIs for communication between Java and C++, the overhead it brings due to its cross-language nature is huge. According to our research, the overhead that JNI may introduce in actual large-scale graph computing scenarios mainly comes from the following call overheads.
-
The overhead of JNI function calls. There is already a considerable overhead in calling the JNI function itself, including accessing Java Objects in the JNI code implementation, which is a very time-consuming operation.
-
Java native methods cannot be inlined by the JVM. In Java, optimization of code is mainly done by the JVM. For frequently called Java methods, the JVM can avoid the overhead of function calls by inlining them. However, for native methods implemented by JNI, the JVM cannot optimize them. In data-intensive scenarios such as graph computing, accessing data stored in C++ memory through JNI from Java is a frequent operation. Therefore, native methods that cannot be inlined will be a significant overhead during program execution.
-
Java native methods cannot be optimized by JIT. Native methods have already been compiled into binary code by C++/C compiler, so it is not possible for the JVM to optimize them through JIT.
Challenge 3: Support for User-defined Data Structures
In some complex real-world production scenarios,Users often have a great demand for customizing vertex data type, edge data type, and even message types. Relying solely on JNI cannot achieve this because every time a user defines a new data type, we need to implement it in C++ and then write JNI methods to map it to Java.
Design and Implementation
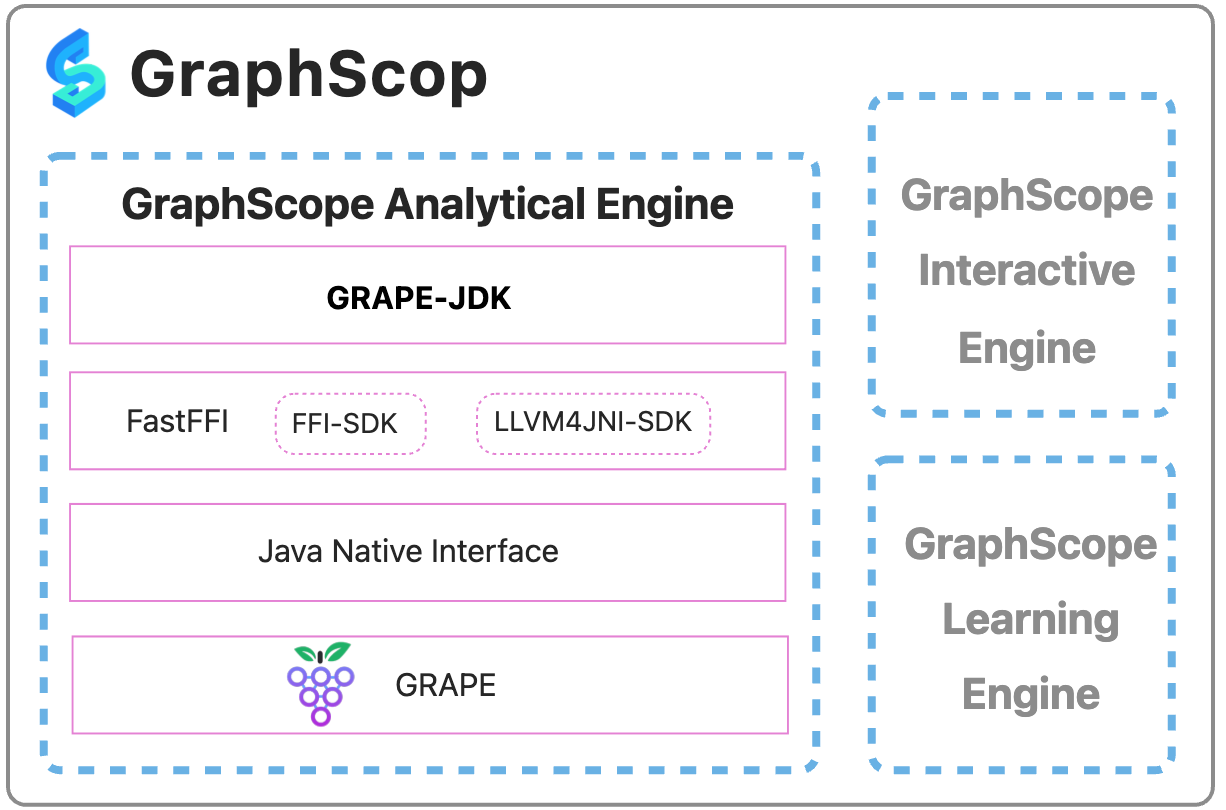
To overcome these challenges, the GraphScope team worked closely with the JVM team at Alibaba Cloud Programming Language and Compiler to design and implement a high-performance and user-friendly cross-language graph computing solution. At the same time, the development of GRAPE-JDK also led to a modern and advanced FFI (Foreign Function Interface) framework: FastFFI (open-sourced on GitHub: alibaba/fastFFI. The position of GRAPE-SDK in the GraphScope system is shown below.
FastFFI
The functionality of GRAPE-JDK depends on FastFFI. FastFFI is a modern, advanced, and efficient Java FFI framework whose features are derived from our exploration of cross-language programming between Java and C++ in GRAPE-JDK. FastFFI successfully overcomes the three challenges mentioned above.
| Challenge | Solution |
|---|---|
| The difficulty of JNI programming | FastFFI’s code generation framework |
| Huge overhead of cross-language access | FastFFI’s LLVM4JNI: Converting LLVM bitcode to Java Bytecode. |
| Support for user-defined data structures | FastFFI’s @FFIMirror technique |
FastFFI can be divided into two parts, FFI-SDK and LLVM4JNI-SDK. FFI-SDK provides comprehensive JNI development support, reducing the complexity of programming. LLVM4JNI-SDK provides JNI code optimization support to improve runtime performance. For more information about FastFFI, please refer to FastFFI.
GRAPE-JDK
Based on the JNI support provided by FastFFI, we developed the Java PIE SDK for GRAPE: GRAPE-JDK. Taking Vertex as an example, we will introduce how FastFFI reduces the complexity of JNI development and improves performance.
The Mapping between C++ and Java Classes
As the most basic abstraction in the graph, Vertex often has a unique ID and attribute (vertex data). For example, in GRAPE, the interface abstraction of a vertex is as follows
template <typename T>
class Vertex {
public:
Vertex() {}
~Vertex() {}
//Other code fragments are omitted here, see full code at
// https://github.com/alibaba/libgrape-lite/blob/master/grape/utils/vertex_array.h#L36
// Get the id bound with this vertex.
inline T GetValue() const { return value_; }
// Set the id bound with this vertex.
inline void SetValue(T value) { value_ = value; }
private:
T value_;
}
In order to map the C++ Vertex class to Java, all we need to do is to write the following code in Java.
@FFIGen(library = "grape-jni")
@CXXHead("grape/utils/vertex_array.h")
@FFITypeAlias("grape::Vertex")
@CXXTemplate(
cxx = {"uint64_t"},
java = {"Long"})
public interface Vertex<VID_T> extends FFIPointer {
VID_T GetValue();
void SetValue(VID_T id);
}
@FFIGen and @CXXHead are both Java annotations. By providing additional information through annotations, we can generate code
during the compilation of Java code. For example, @CXXHead("grape/utils/vertex_array.h") specifies that the generated
C++ code needs to include the header file grape/utils/vertex_array.h.
After compilation, Vertex.java will generate two sets of code, one of which is the implementation
class of the Java Vertex interface, which defines the corresponding native methods.
public class Vertex_cxx_0xaccf3424 extends FFIPointerImpl implements Vertex<Long> {
public Vertex_cxx_0xaccf3424(final long address) {
super(address);
}
public Long GetValue() {
return new java.lang.Long(nativeGetValue(address));
}
//The actual working native method.
public static native long nativeGetValue(long ptr);
public void SetValue(Long arg0) {
nativeSetValue(address, arg0);
}
// The actual working native method.
public static native void nativeSetValue(long ptr, long arg00);
}
Also, there will be a .cc file containing the implementation of the native methods after compilation
// headers are omitted.
#ifdef __cplusplus
extern "C" {
#endif
JNIEXPORT
jlong JNICALL Java_com_alibaba_graphscope_ds_Vertex_1cxx_10xaccf3424_nativeGetValue(JNIEnv*, jclass, jlong ptr) {
return (jlong)(reinterpret_cast<grape::Vertex<uint64_t>*>(ptr)->GetValue());
}
JNIEXPORT
void JNICALL Java_com_alibaba_graphscope_ds_Vertex_1cxx_10xaccf3424_nativeSetValue(JNIEnv*, jclass, jlong ptr, jlong arg0 /* arg00 */) {
reinterpret_cast<grape::Vertex<uint64_t>*>(ptr)->SetValue(arg0);
}
#ifdef __cplusplus
}
#endif
Similarly, we can map any C++ class to a Java class.
FFIMirror:User-defined Data Structures
In GRAPE-JDK, we support users to create a customized data structure that has no corresponding C++ implementation, and use it as the data type for vertex ID, vertex or edge. You only need to use the @FFIMirror annotation to decorate your own defined interface. For example, we can define a simple data structure containing only long and double fields. During compilation, the corresponding C++ code, JNI code, and Java implementation class code will be automatically generated.
@FFIMirror
@FFINameSpace("sample")
@FFITypeAlias("MyData")
public interface MyData extends CXXPointer {
//Get the long field.
@FFIGetter long longField();
//Set the long field.
@FFISetter void longField(long value);
@FFIGetter double doubleField();
@FFISetter void doubleField(double value);
//Create MyData with this factory
MyData.Factory factory = FFITypeFactory.getFactory(MyData.class);
@FFIFactory
interface Factory {
MyData create();
}
}
Next, similar to regular JNI projects, after compiling the obtained .cc files and linking them into a dynamic library,
we can load them into Java through System.loadLibrary() and access C++ objects and methods in Java
As we can see, the implementation of GRAPE-JDK based on FastFFI perfectly solves the difficulties in development, debugging, and maintenance in cross-language programming with JNI, and meets the needs of users for customized data types
Optimizing JNI
LLVM4JNI-SDK is a “BitCode to ByteCode” conversion tool implemented entirely in Java. The working principle of LLVM4JNI
is to analyze LLVM-IR (JNI code is embedded in the dynamic library binary by using option -mllvm=-lto-embed-bitcode
when compiling with LLVM11), select the code that can be converted to Java bytecode (not all LLVM IR can be converted to bytecode),
generate bytecode, and finally replace the corresponding Java native methods.
For example, for the Vertex defined earlier, when running LLVM4JNI for optimization, we will replace the native methods in the Vertex implementation class:
public class Vertex_cxx_0xaccf3424 extends FFIPointerImpl implements Vertex<Long> {
//Notice that this a no longer a native method now!
public static long nativeGetValue(long ptr){
return JavaRuntime.getLong(var0);
}
public static void nativeSetValue(long ptr, long arg00){
JavaRuntime.putLong(ptr, arg00);
}
}
As we can see in lines 3 and 7, the original native methods are replaced with normal Java methods,
and the implementation in the methods uses JavaRuntime, which is a wrapper for Java
UNSAFE in LLVM4JNI-runtime and essentially still uses UNSAFE to access off-heap memory.
By replacing native methods with Java methods, we avoid significant overhead in JNI calls
User Interface
By exposing only a simple programming model interface, ParallelAppBase, we can hide the complex implementation of GRAPE-JDK.
Users do not need to know anything about the underlying implementation. They only need to inherit the interface and implement
the two methods, PEval and IncEval, to run the algorithm on the GraphScope graph analysis engine.
For more tutorials, please refer to GAE-java-tutorial.
public class Traverse implements ParallelAppBase<Long, Long, Double, Long, TraverseContext>,
ParallelEngine {
@Override
public void PEval(IFragment<Long, Long, Double, Long> fragment,
ParallelContextBase<Long, Long, Double, Long> context,
ParallelMessageManager messageManager) {
}
@Override
public void IncEval(IFragment<Long, Long, Double, Long> fragment,
ParallelContextBase<Long, Long, Double, Long> context,
ParallelMessageManager messageManager) {
}
}
public class TraverseContext extends
VertexDataContext<IFragment<Long, Long, Double, Long>, Long> implements ParallelContextBase<Long,Long,Double,Long> {
@Override
public void Init(IFragment<Long, Long, Double, Long> frag,
ParallelMessageManager messageManager, JSONObject jsonObject) {
}
@Override
public void Output(IFragment<Long, Long, Double, Long> frag) {
}
}
Performance
To verify the running performance of GRAPE-JDK in large-scale graph computing scenarios, we conducted tests on datasets with hundreds of millions of vertices and billions of edges provided by LDBC Graphalytics for various common algorithms. The test configuration was 4 clusters with 400GB of memory and 96 cores, and 4 GraphScope workers. For specific performance test report results, please refer to GRAPE-JDK performance report. Here we take the SSSP and PageRank algorithms as examples to show the experimental results.
Java App vs C++ App
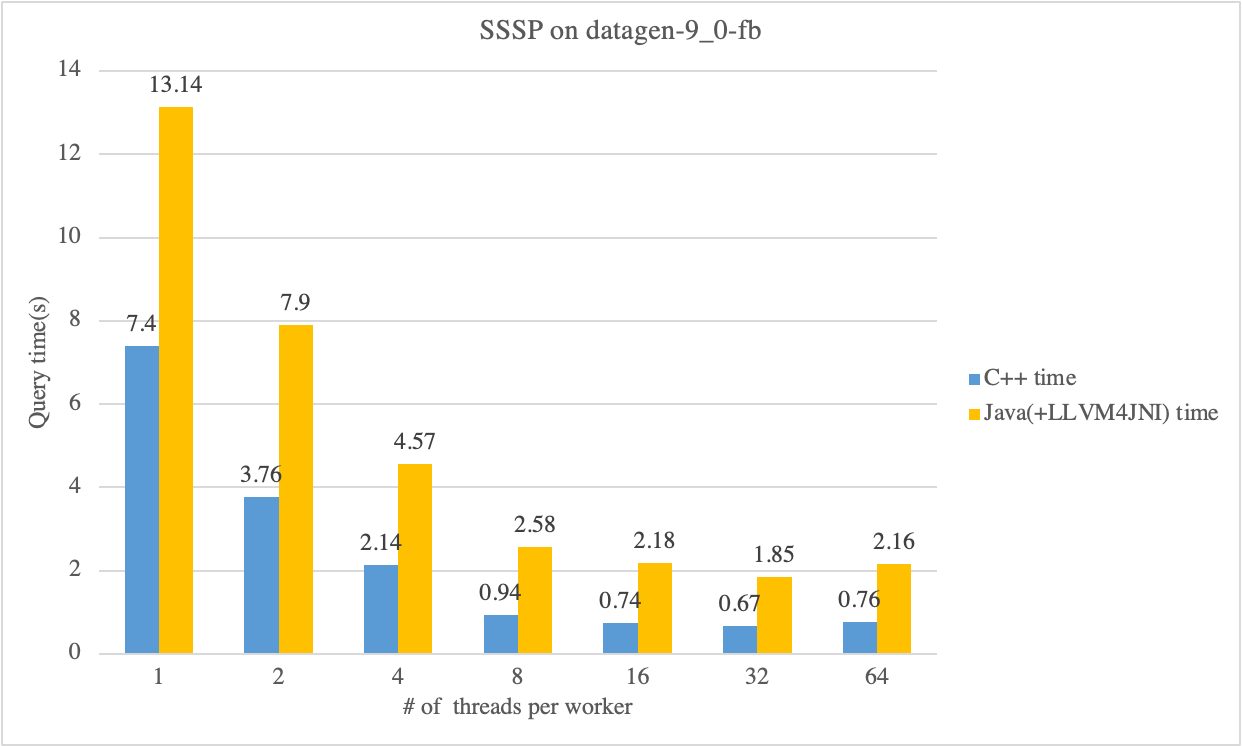
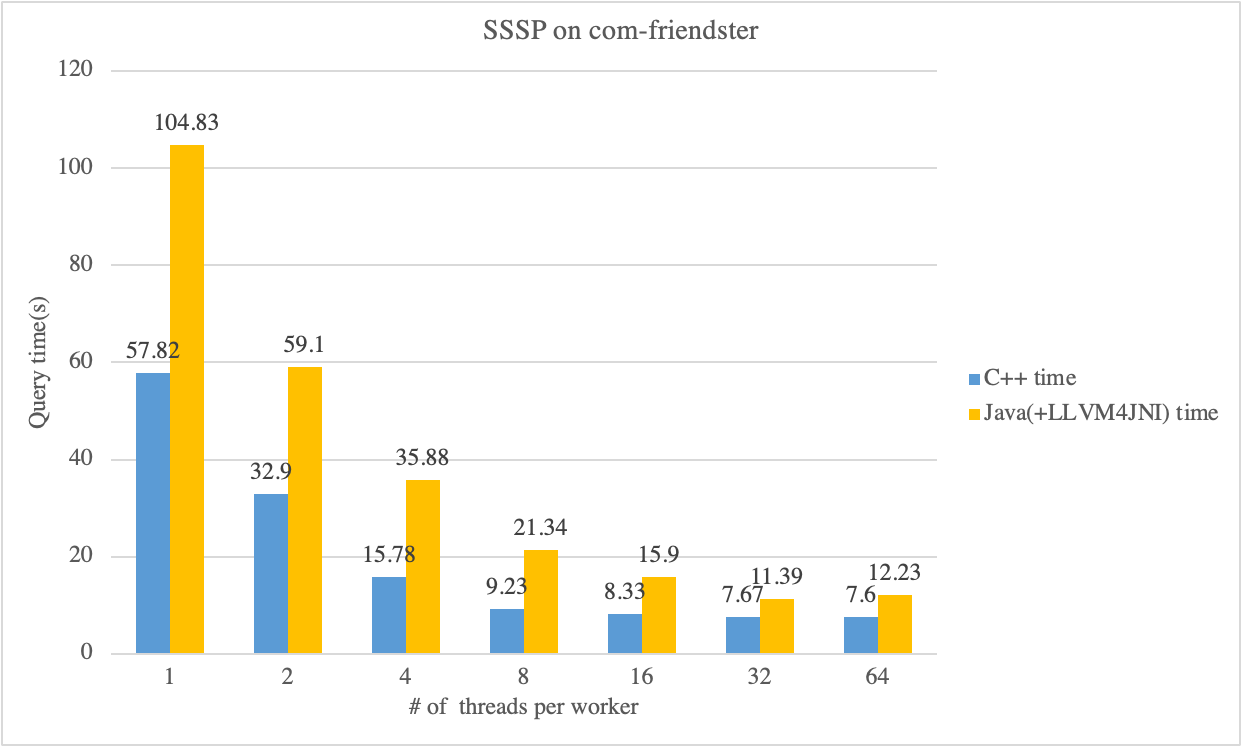
First, we compare the performance gap between the Java-SSSP algorithm based on GRAPE-JDK and the CPP-SSSP algorithm based on libgrape-lite on the com-fiendster and Datagen-9_0-fb datasets. We can see that the overall performance gap between the Java app and the C++ app is about 2 times.
Performance Improvement Brought by LLVM4JNI
LLVM4JNI has brought significant performance improvements to GRAPE-JDK. As shown in the table below, the Java-PageRank algorithm implemented using GRAPE-JDK is now approaching the performance of CPP-PageRank. In cases with high concurrency, the time is very close to C++ (such as the column with a concurrency of 32 in the second table).
Performance result is shown in the following two tables.
| threads | 1 | 2 | 4 | 8 | 16 | 32 | 64 | |
|---|---|---|---|---|---|---|---|---|
| Com-friendster | C++ time | 567 | 325 | 149 | 78 | 39 | 37 | 43 |
| Com-friendster | Java time | 3166 | 1651 | 621 | 373 | 197 | 107 | 147 |
| Com-friendster | Java(+LLVM4JNI) time | 743 | 377 | 202 | 99 | 53 | 38 | 48 |
| threads | 1 | 2 | 4 | 8 | 16 | 32 | 64 | |
|---|---|---|---|---|---|---|---|---|
| datagen-9_0-fb | C++ time | 253 | 113 | 65 | 33 | 22 | 17 | 17 |
| datagen-9_0-fb | Java time | 1439 | 770 | 358 | 162 | 85 | 64 | 74 |
| datagen-9_0-fb | Java(+LLVM4JNI) time | 393 | 172 | 85 | 41 | 26 | 23 | 22 |
Conclusion
In this blog, we briefly introduce GRAPE-JDK, a cross-language graph analysis toolkit foe GraphScope. With the help of the modern FFI framework FastFFI, GRAPE-JDK not only provides a friendly user interface for Java users but also has efficient graph query performance. We welcome everyone to try GRAPE-JDK tutorial and provide valuable feedback on usage suggestions.