GraphAr: A Standard Data File Format for Graph Data Storage and Retrieval
 In this post, we will introduce GraphAr, which is an open source, standard data file format for graph data storage and retrieval. It defines a standardized file format for graph data, independent of the computation/storage system, and provides a set of interfaces for generating, accessing, and transforming these formatted files.
In this post, we will introduce GraphAr, which is an open source, standard data file format for graph data storage and retrieval. It defines a standardized file format for graph data, independent of the computation/storage system, and provides a set of interfaces for generating, accessing, and transforming these formatted files.
Background
With the development of applications such as social network analysis, data mining, and scientific computing, graph computation has become increasingly important as a crucial part of analyzing massive amounts of data. There have been various graph storage, database, graph analytical systems, and interactive graph query engines based on memory or disk in the industry. Due to the fragmented nature of the graph computation ecosystem, with different data formats and access patterns, there is a need for a standardized file format and access interface to address the challenges of data import/export and interoperability among different graph computation systems.
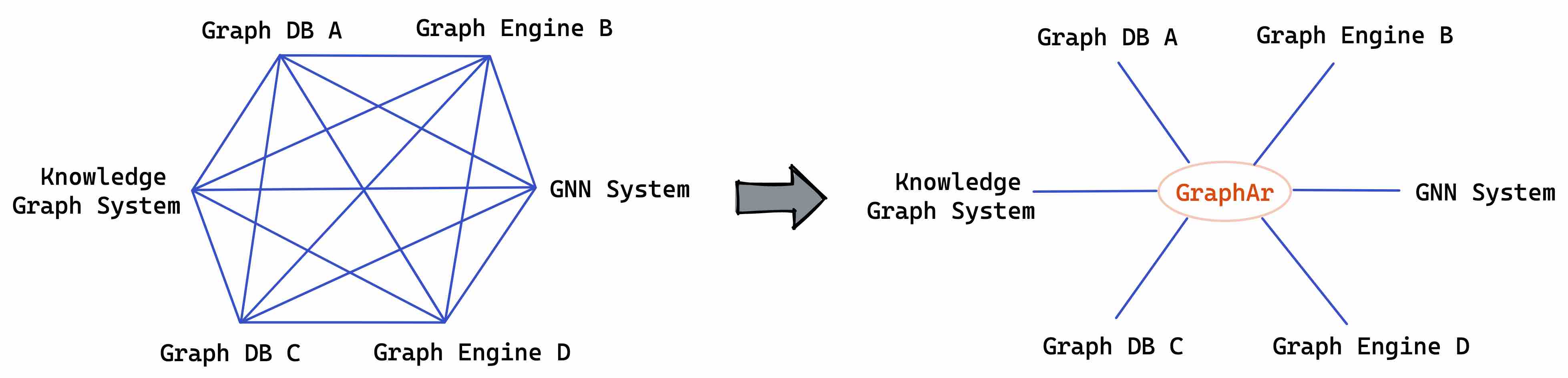
GraphAr (Graph Archive, or GAR for short) is designed for this purpose. It defines a standardized file format for graph data, computation/storage system independent, and provides a set of interfaces for generating, accessing, and transforming these formatted files. GraphAr facilitates the construction and access of graph data for various graph computation applications or existing systems, serving as both a direct data source for graph computation applications and supporting data import/export and persistent storage for graph data, reducing the overhead of collaboration among different graph systems.
Design Principles
To accommodate the diverse storage and access requirements of various systems for graph data, the design of the GraphAr standardized graph file format considers the following points:
- Leveraging existing file formats, such as ORC, Parquet, CSV;
- Supporting both simple graph and property graph, with support for different representations of graph topology structures (COO, CSR, and CSC).
- Easy to generate, load or transform with Apache Spark/Hadoop.
- Facilitating loading by different single or distributed graph computation engines and databases, as well as supporting various downstream computing tasks like out-of-core graph computation.
- Supporting routine operations without modifying the payload files, such as adding new properties, adding a group of new types of vertices/edges to a graph or construct a new graph with different types and vertex and edge.
Property Graph Model
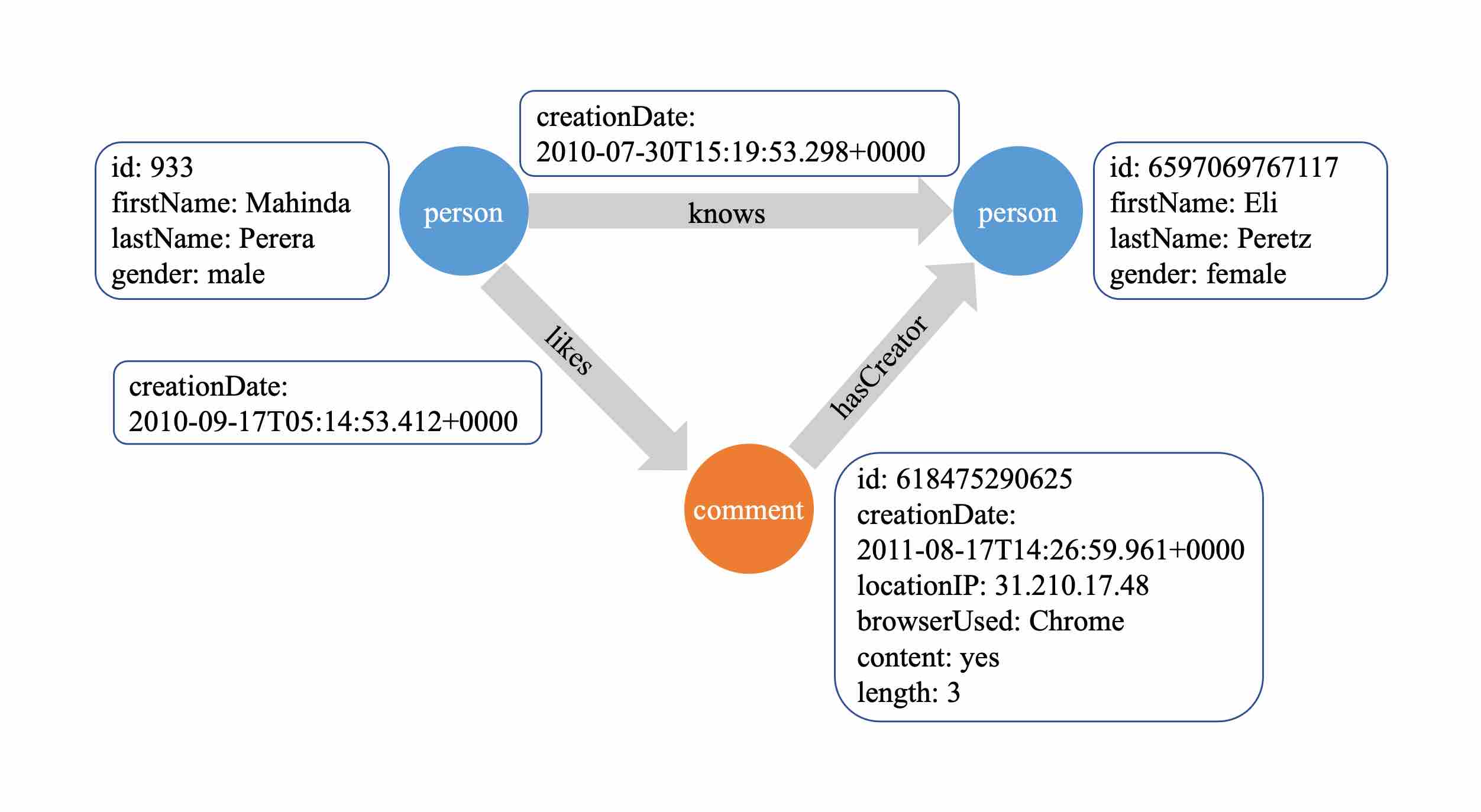
GraphAr models graph data as labeled property graphs. A graph is a data structure composed of vertices and edges, while a labeled property graph allows vertices/edges to carry labels (also called types or tags) and some properties. As property graphs contain more information than non-property graphs, they can better express the relationships and data dependencies among different types of entities, making them widely used in applications such as social network analysis and data mining. The figure below shows a property graph that includes two types of vertices (“person” and “comment”) and three types of edges (“knows”, “likes” and “hasCreator”).
Vertex Data Storage
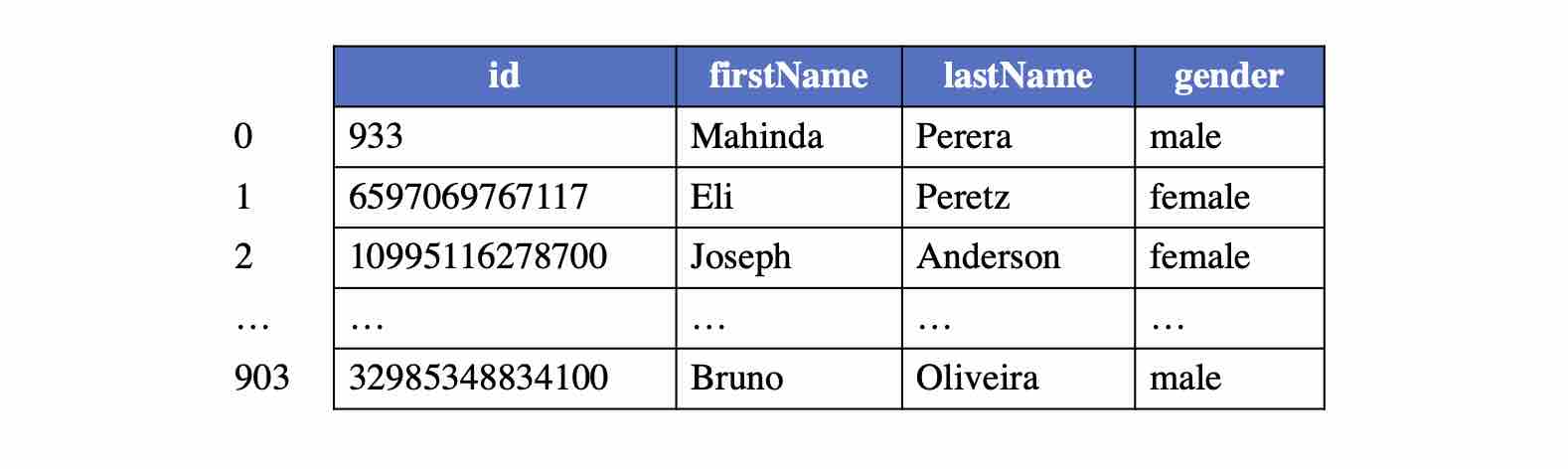
In GraphAr, each type of vertex constitutes a logical vertex table, where each vertex is assigned a global index starting from 0 (i.e., vertex index), corresponding to the row number in the logical vertex table. Given a vertex type and a vertex index, a vertex can be uniquely identified to retrieve its related properties from the table. The figure below represents the logical vertex table corresponding to the “person” type of vertices.
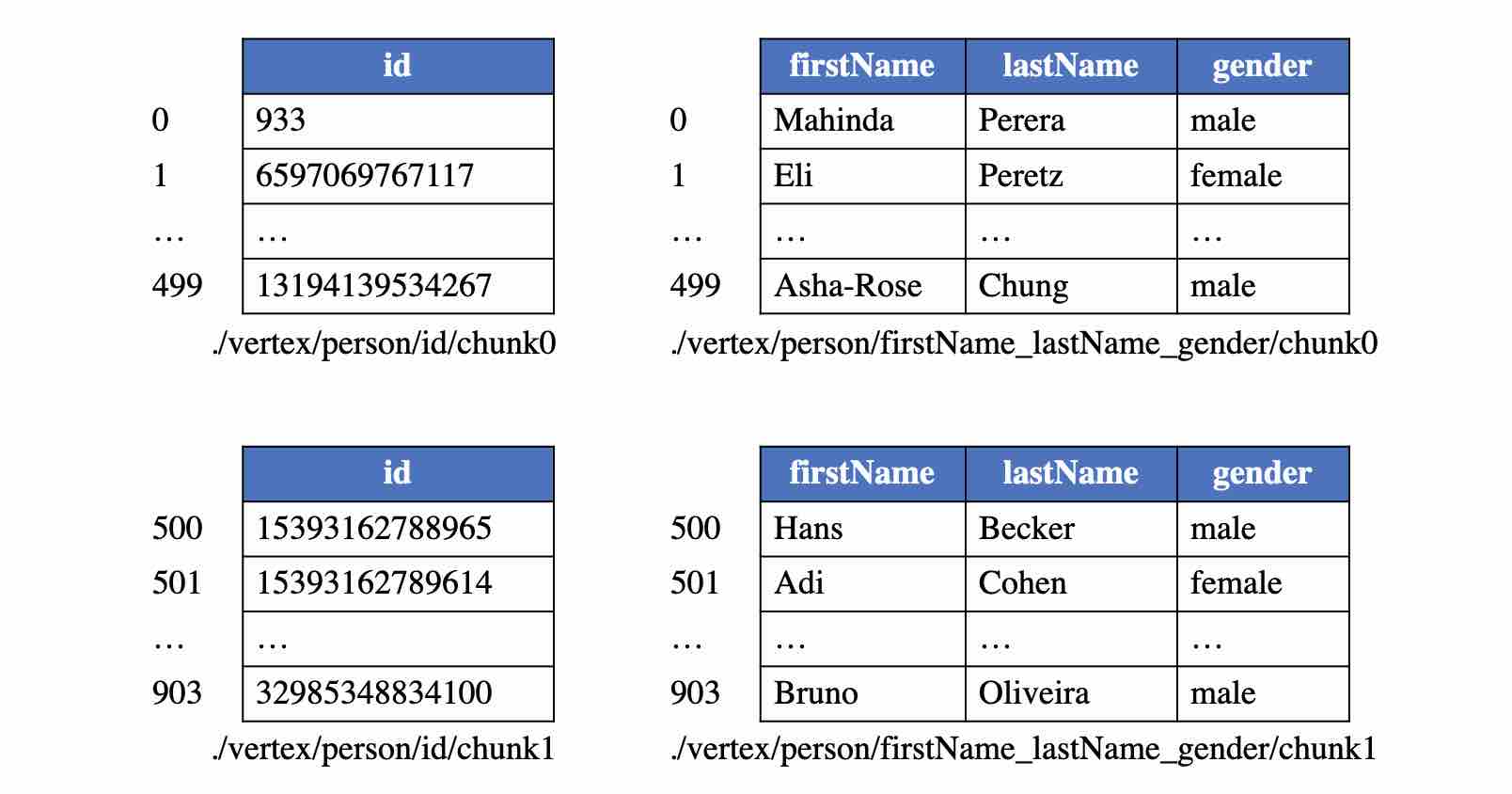
In actual storage, the logical vertex table is divided into multiple continuous subtables or partitions. Each subtable of the same vertex table has a fixed size (except for the last subtable, which may be smaller than the specified value), and the vertex indices it contains are continuous. Additionally, to facilitate accessing specific property columns and adding new properties without modifying existing files, the property columns of the logical vertex table are also divided into multiple column groups. Taking the above logical vertex table as an example, if the point data block size is set to 500 and the four properties are divided into two groups, a total of four physical tables (corresponding to four point data blocks in the disk) will be created, as shown in the figure below.
Edge Data Storage
Similarly, in GraphAr, each type of edge forms a logical edge table. To support fast data reading from files and creating an in-memory graph structure, the logical edge table can maintain the topological information of the graph in a format similar to CSR/CSC (compressed sparse row or compressed sparse column format) by sorting the edges based on the source or destination vertex index. If the logical edge table is recorded in this ordered manner, an additional offset table is required to store the starting positions of each edge corresponding to each vertex.
According to the edge partition strategy and order, there are four types of edge tables in GraphAr: partitioned by source vertex and ordered, partitioned by source vertex and unordered, partitioned by destination vertex and ordered, and partitioned by destination vertex and unordered. Taking the “person knows person” type of edges as an example, if the type is partitioned by source vertex and ordered, the corresponding logical edge table is shown below:
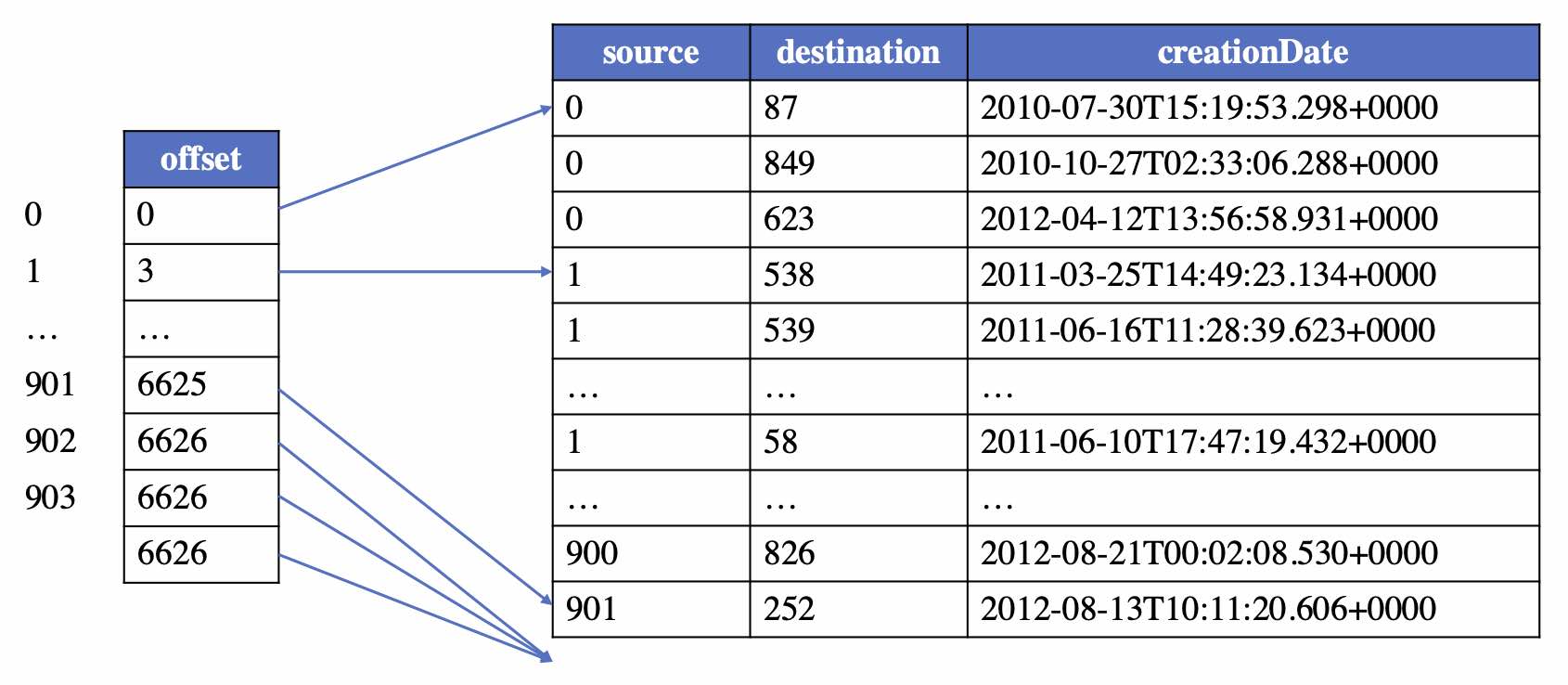
Each logical edge table can have three types of physical edge tables:
- Adjacency table (containing only two columns: the source and destination vertex indices)
- Edge property table
- Offset table (only applicable to ordered edges)
Since the logical vertex table is partitioned into multiple data chunks, the logical edge table will also be initially divided into subtables, where each subtable ensures that the source (in the case of partitioning by source vertex) or destination (in the case of partitioning by destination vertex) vertices are within the same vertex partition. Then, each sub-logical edge table is further divided into smaller subtables according to the specified size of the edge data chunk. Finally, these subtables are split by column to form physical edge tables representing adjacency tables and various groups of edge properties, i.e., edge data chunks. The partitioning of the offset table aligns with the partitioning of the corresponding vertex table. Following these rules, the above logical edge table will be stored in the following physical edge tables:
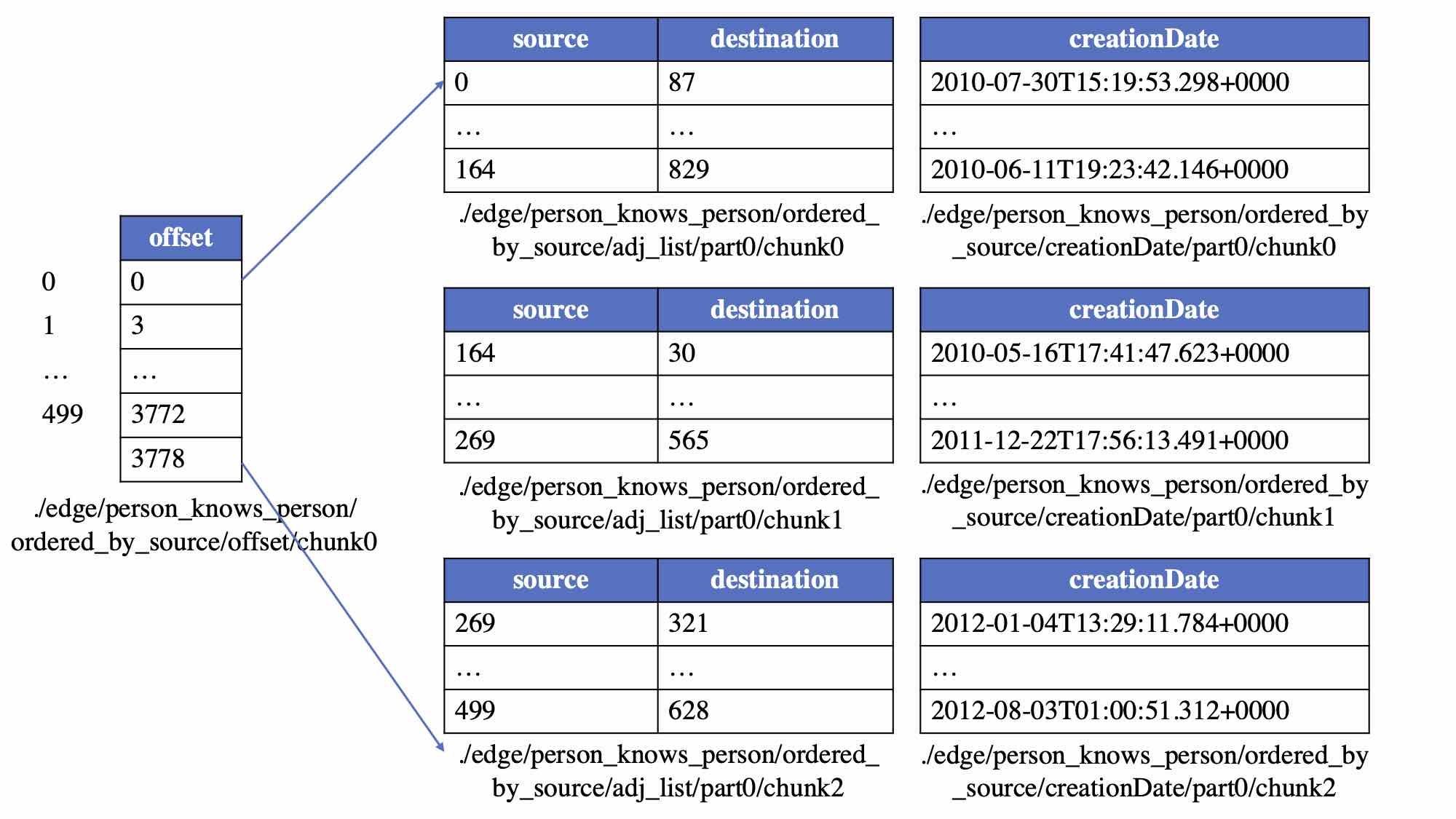
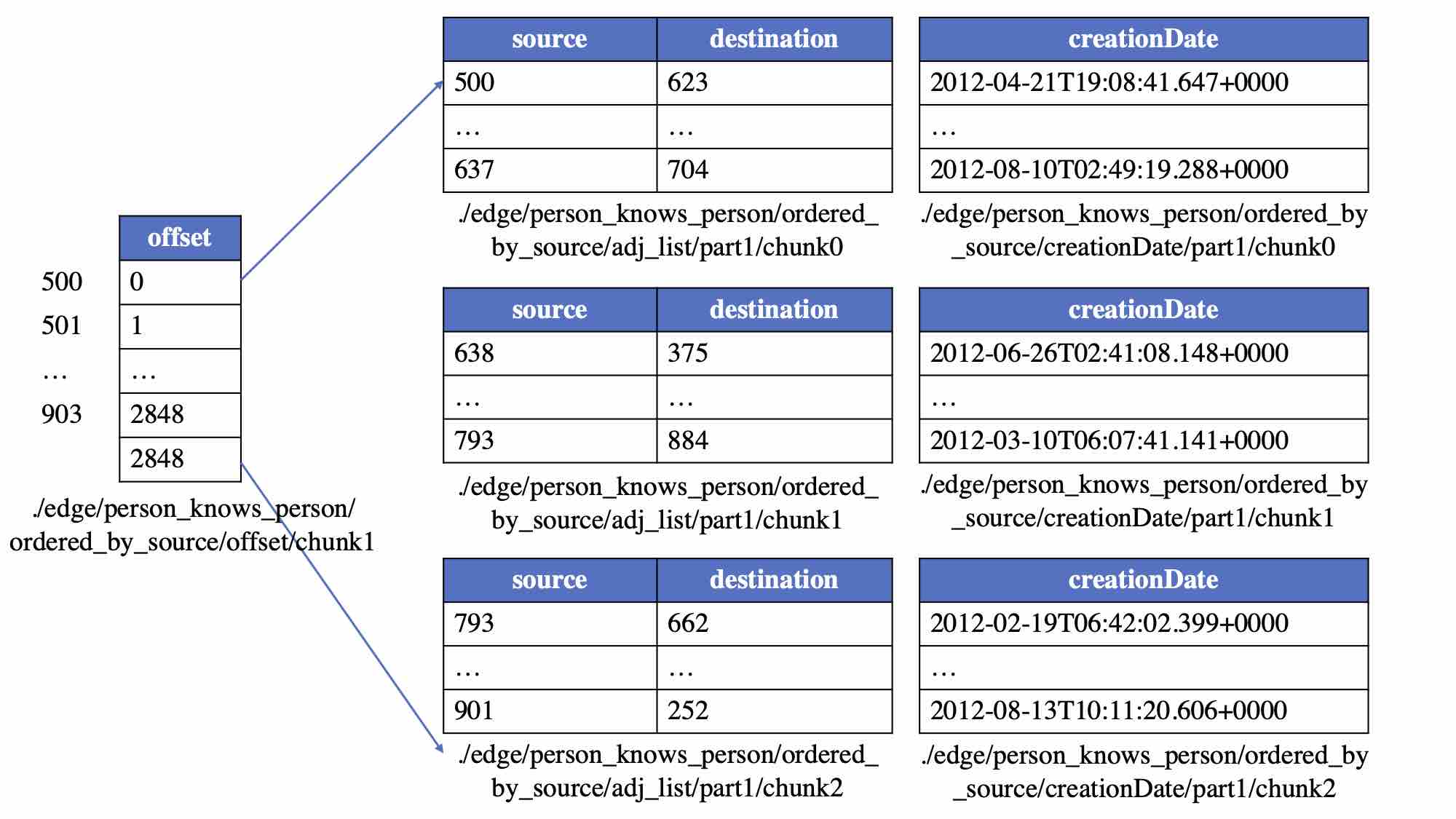
File Storage
GraphAr stores metadata and data chunks in separate files. The metadata is described using a set of YAML files, with each graph instance corresponding to a graph information file and each type of vertex/edge corresponding to a vertex/edge information file. These YAML files define all the necessary information about how graph data is stored in GraphAr, such as the types of vertices and edges in a graph, the storage paths for data chunks, the data chunk sizes for each type of vertex/edge, the partitioning and ordering of edges, the attributes included in each attribute group, their types, and the file formats they are stored in, etc.
Each data chunk is stored as an actual file in a specified directory in the format specified in the metadata. The file type can be ORC, Parquet, or CSV. Since ORC and Parquet are widely used columnar storage formats, GraphAr supports accessing specific attribute columns to avoid reading irrelevant attributes during graph computation, thereby improving performance.
Project Overview
The open-source GraphAr project currently includes the following components:
- Definition of the standardized graph storage file format
- A C++ SDK for building GraphAr metadata and reading or writing data chunk files, providing support for out-of-core graph computation through abstracted access interfaces
- A Spark SDK for efficient, convenient, and scalable batch generation, loading, or transformation of GraphAr files using Apache Spark. It can also be used to integrate with other Spark-compatible systems like GraphX and Neo4j.
- Examples of implementing out-of-core graph algorithms using GraphAr and integration cases with existing systems like GraphScope.
The GraphAr project is continuously being developed and updated, with upcoming features including:
- Support for more data types, file systems, and file formats.
- Providing SDKs for more programming languages.
- Offering more flexible and user-friendly interfaces, as well as further optimizing read/write performance.
- Providing a CLI tool for easy and intuitive management and inspection of stored instances in GraphAr.
Applications
GraphAr is already being applied in various scenarios, with some implemented use cases including:
-
Serving as a direct data source, supporting various out-of-core graph computation algorithms through the access interface of GraphAr files. This enables the analysis and processing of massive graph data using limited memory/computing resources on a single machine. Implementations of some typical algorithms (including PageRank, BFS, weakly connected components, etc.) are provided in the GraphAr code repository.
-
Supporting different single/distributed graph computation engines to load data from GraphAr files and construct their corresponding in-memory graph structures for subsequent calculations. The systems that have been connected include BGL (Boost Graph Library), Spark GraphX, and GraphScope. Due to the rich graph semantics provided by the GraphAr format and its efficient access interface, it can improve graph loading speed. In actual business scenarios at Alibaba, it has optimized the graph loading speed of GraphScope to 6 times faster.
-
Serving as a data export and persistent storage archive format. Currently, we have integrated GraphAr’s Spark SDK with the typical graph database system Neo4j, enabling the export of data from Neo4j database to GraphAr files for data archiving, as well as reading graph data from GraphAr files and adding/updating it into the Neo4j database.
Conclusion
In the field of graph computation, there are challenges such as fragmented system ecosystems, diverse access requirements, and lack of standardized data formats. Data import/export between different systems often becomes a cumbersome and complex process, requiring significant human effort and time. GraphAr aims to address these challenges by establishing a simple, efficient, and universal standardized file format and related interfaces, serving the data access, import/export, and persistent storage needs of various graph computation systems and applications.