GraphScope Flex: LEGO-like Graph Computing Stack
 From June 9th to June 15th, 2024, SIGMOD 2024 was held in Santiago, Chile.
The GraphScope team presented their paper “GraphScope Flex: LEGO-like Graph Computing Stack” at the SIGMOD Industry Session.
This article introduces the main content of that paper.
From June 9th to June 15th, 2024, SIGMOD 2024 was held in Santiago, Chile.
The GraphScope team presented their paper “GraphScope Flex: LEGO-like Graph Computing Stack” at the SIGMOD Industry Session.
This article introduces the main content of that paper.
Diversified Graph Computing Demands
Graph computing encompasses a wide range of types, commonly including graph analytics, graph interactive queries, and graph neural networks (GNNs). Previous graph computing systems typically cater to a specific type of graph computation. In a complex workflow, which may involve multiple types of graph computing tasks, users often need to employ multiple graph computing systems to complete this intricate process.
To address these issues, we developed and open-sourced the industry’s first one-stop graph computing system, GraphScope, in 2020. As illustrated in the figure below, GraphScope integrates a Graph Analytics Engine (GAE), a Graph Interactive Engine (GIE), and a Graph Learning Engine (GLE) to support different types of graph computations. Additionally, GraphScope includes an immutable in-memory graph storage system called Vineyard, which allows various computing engines to share data through shared memory. To reduce the learning curve for users, GraphScope extends Gremlin as a unified query language and offers a simple and user-friendly Python interface.
In real scenarios, we find that the demand for graph computing is highly diverse. The diagram below illustrates Alibaba’s real graph computing scenarios, where graph data may consist of immutable data stored in memory, may come from external data sources that are continuously updated, or may originate from files in a data lake. The workloads of graph computing are also quite varied. For example, Workload 1 represents running a ranking algorithm (e.g., PageRank) on the graph, which is a typical graph analytics task. Workload 2 represents running a fraud detection model based on graph neural networks on the graph. Workload 3 requires processing a large number of queries related to product recommendations in a short amount of time. Workload 4 represents the need to perform real-time online query operations on graph data through a WebUI, while Workload 5 represents data analysts needing to conduct BI analysis on graph data, aiming to obtain analytical results in the shortest time possible.
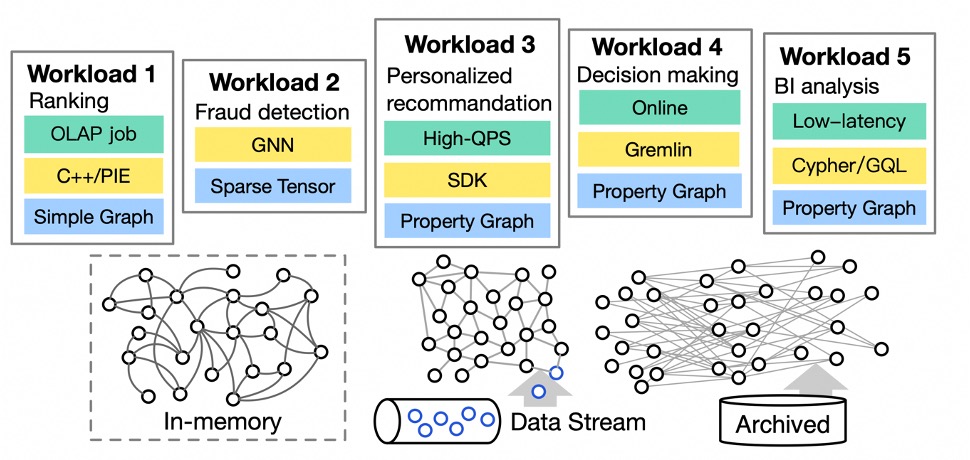
From the examples mentioned above, it is clear that the diversity of graph computing is reflected in various aspects such as storage, workloads, and performance metrics of interest. In light of this diversity, the one-stop design of GraphScope appears inadequate to handle such varied requirements.
Diversity of Graph Types and Storage
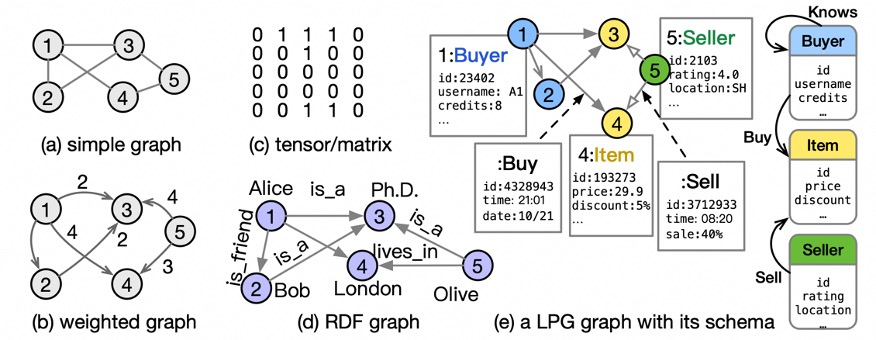
Firstly, there is a diversity in both graph types and graph storage. On one hand, there are multiple graph representation models currently available, as illustrated below. Common models include simple graphs, weighted graphs, sparse matrices/tensors, labeled property graphs, and RDF (Resource Description Framework) graphs. On the other hand, the storage characteristics of graph data also exhibit diversity, including in-memory vs. external storage, mutable vs. immutable data, and support for multi-versioning, among others. Therefore, the use of the property graph model with immutable in-memory storage, such as Vineyard in GraphScope, struggles to adapt to this diversity.
Diversity of Graph Computing Paradigms and Query Interfaces
Secondly, the types of graph computing are highly diverse, encompassing various workloads such as graph analytics, graph querying, and graph neural networks. Moreover, different types of graph computing tasks typically employ different programming interfaces and query languages. Even within the same type of graph computation, there are multiple commonly used programming interfaces and query languages, making it difficult to expect users to express all workloads using a single, unified interface or language. For example, common programming interfaces for graph analytics tasks include Pregel, GAS, and PIE, while frequently used query languages in the graph querying domain include Gremlin, Cypher, and GQL. Additionally, popular graph neural network systems like DGL and PyG utilize different programming interfaces. Consequently, the use of a unified programming/query language in GraphScope faces challenges in addressing the diversity of computing paradigms and query interfaces.
Diversity of Performance Requirements in Graph Computing
Finally, even with the same data and the same type of workload, the performance metrics we focus on may vary across different scenarios. For example, in tasks related to graph querying, when faced with a scenario that requires handling a large number of simple queries in a short time, our primary performance metric is system throughput. Conversely, in a scenario involving a small number of complex queries, the focus shifts to low latency, meaning that the system must return results for individual queries in the shortest time possible. Since any given system or component is typically optimized for a specific performance metric, a single component in GraphScope struggles to effectively meet multiple performance requirements simultaneously.
GraphScope Flex: Modular Design Inspired by LEGO
To better address the increasingly diverse needs of graph computing, we have designed the next-generation architecture of GraphScope, known as GraphScope Flex. This architecture adopts a modular design philosophy, allowing users to freely select appropriate components based on specific task requirements, much like building with LEGO bricks.
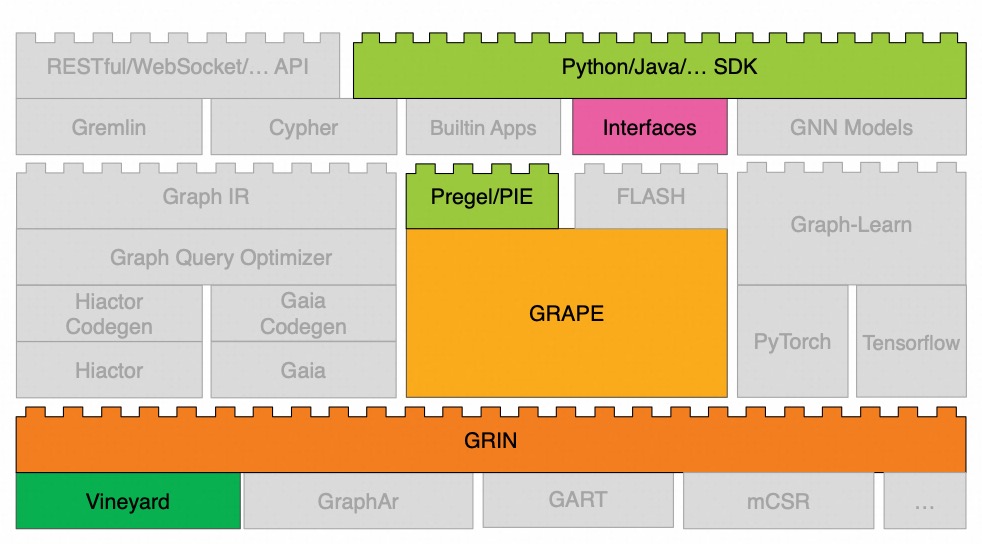
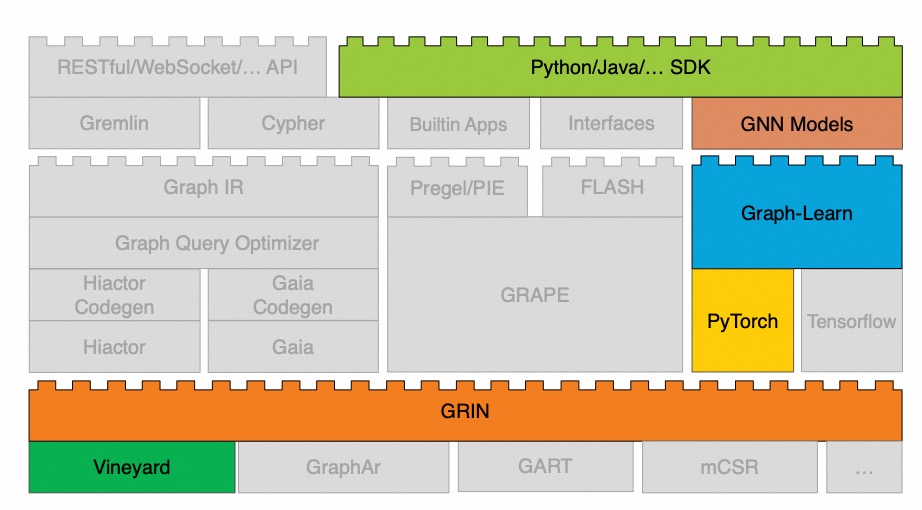
The architecture of GraphScope Flex, as shown in the diagram below, is divided into three layers: the storage layer, the execution engine layer, and the frontend layer. Each layer contains a rich set of components that have been highly optimized for different objectives.
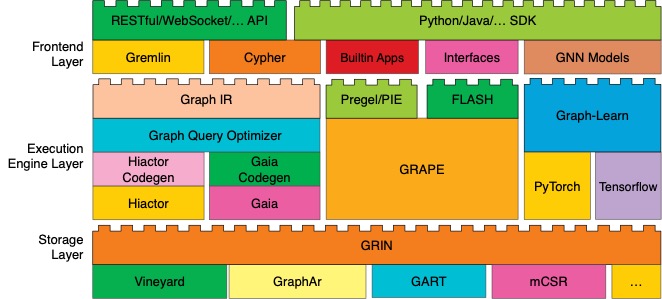
When given a specific task, users simply need to select the components that meet their requirements from each layer. They can then use the building tool, flexbuild, provided by GraphScope Flex to construct a graph computing system tailored to their needs. Specifically, each layer in GraphScope Flex includes the following components.
Storage Layer
The storage layer currently supports several types of storage: immutable in-memory storage (Vineyard), standard data file format for graph (GraphAr), multi-version mutable storage (GART), and mutable in-memory storage (mCSR). Each storage type has different access interfaces. To shield the execution engines from the interface discrepancies of various storage types, GraphScope Flex adopts a standardized graph access interface called GRIN, requiring all storage implementations to comply with this interface. This way, all upper-layer computing engines can access all graph storage using a single, uniform interface. In the future, if new storage options are added to the storage layer, users won’t need to worry about compatibility issues resulting from these extensions.
Execution Engine Layer
GRAPE is a high-performance distributed engine designed for graph analysis tasks, optimized for computation and communication on the CPU. Recently, it has introduced support for GPU, leveraging the high computing power of GPUs and high-speed interconnects like NVLink to accelerate graph analysis tasks. GRAPE provides external programming models such as Pregel, PIE, and FLASH, facilitating the development of customized graph analysis algorithms for users.
For graph querying tasks, the GraphIR module translates user-written queries in Cypher or Gremlin into a query language-agnostic intermediate representation. The Graph Query Optimizer module employs both Rule-based Optimization (RBO) and Cost-based Optimization (CBO) techniques to optimize this intermediate representation. Depending on the performance metrics of interest, the Hiactor Codegen module generates physical execution plans that can be executed on the Hiactor component, a low-level parallel engine suitable for high-throughput scenarios. If the goal is to minimize the execution time of individual queries, the Gaia Codegen module will generate physical execution plans for execution on the Gaia component, a dataflow engine that automatically parallelizes queries to reduce execution time.
To support graph neural networks, the Graph-Learn module handles graph sampling operations, offering support for both CPU and GPU. On the GPU platform, it incorporates an efficient caching mechanism to further accelerate the graph sampling speed. Additionally, the back-end tensor execution module supports both PyTorch and TensorFlow, allowing users to choose according to their needs.
Frontend Layer
The frontend layer includes a rich set of algorithm packages and provides various SDKs and APIs for external services. The Builtin Apps module includes common graph analysis algorithms, such as PageRank and shortest path. The GNN Models module encompasses popular graph neural network models like GCN, PinSAGE, and GraphSAGE. The Cypher and Gremlin modules allow users to perform graph query operations directly using Cypher and Gremlin query languages. Furthermore, the application layer exposes RESTful/WebSocket APIs, making it easy for users to integrate GraphScope Flex with other systems, and provides C++, Python, and Java SDKs to facilitate the development of custom graph algorithm applications.
Real-World Use Cases of GraphScope Flex
Company Equity Analysis
In the task of company equity analysis, we need to identify the ultimate controller of a company, i.e., the individual who controls more than 50% of the company’s equity. An individual may exert influence through multiple layers of companies, so we need to start from a particular individual and calculate both the equity they directly hold and the equity held through other companies. While this process can be expressed and executed using SQL on a relational database, it is often very inefficient. For instance, on a real dataset containing 300 million individuals/companies and 1.5 billion equity holding records, it can take over an hour in a relational database to compute the desired results without yielding any output.
Given the interconnected nature of equity structures, we can transform this problem into a graph analytics task. First, we need to convert the equity relationships into a graph data structure, where the vertices represent individuals or companies, and the edges represent the equity holding relationships.
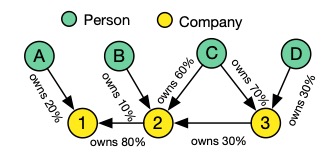
We then select the components illustrated in the diagram below to build a graph analytical system for completing the company equity analysis task.
To achieve higher performance, we choose the in-memory graph storage, Vineyard, for the storage layer.
We select GRAPE as the execution engine for the graph analysis algorithms in the wxecution engine layer.
Users can write the equity analysis logic using the SDK, leveraging the Pregel/PIE interfaces exposed by GRAPE in the frontend layer.
With this configuration, GraphScope Flex can process the same dataset and obtain results in just 15 minutes, demonstrating a significant improvement in efficiency compared to traditional methods. This showcases the flexibility and power of GraphScope Flex in handling complex analysis tasks effectively.
Real-Time Fraud Detection
E-commerce platforms need to perform real-time checks on each order to determine whether it involves fraudulent activities such as order brushing. As shown in the image below, the e-commerce platform has marked a portion of accounts as fraudulent accounts (fraud seeds). We can consider accounts that frequently have a “co-purchase” relationship with these fraudulent accounts as highly suspicious fraudulent accounts as well.
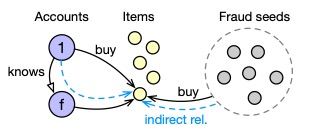
To express the “co-purchase” relationship mentioned above, we can use the following Cypher statement. Therefore, this fraud detection issue is well suited to be transformed into a graph computing problem.
MATCH (v:Account{id:1})-[b1:BUY]->(:Item)<-[b2:BUY]-(s:Account)
WHERE s.id IN SEEDS AND b1.date-b2.date < 5 /*within 5 days*/
WITH v, COUNT(s) AS cnt1
MATCH (v)-[:KNOWS]-(f:Account), (f)-[b1:BUY]->(:Item)<-[b2:BUY]-(s:
Account) WHERE s.id IN SEEDS WITH v, cnt1, COUNT(s) AS cnt2
WHERE w1 * cnt1 + w2 * cnt2 > threshold
RETURN v
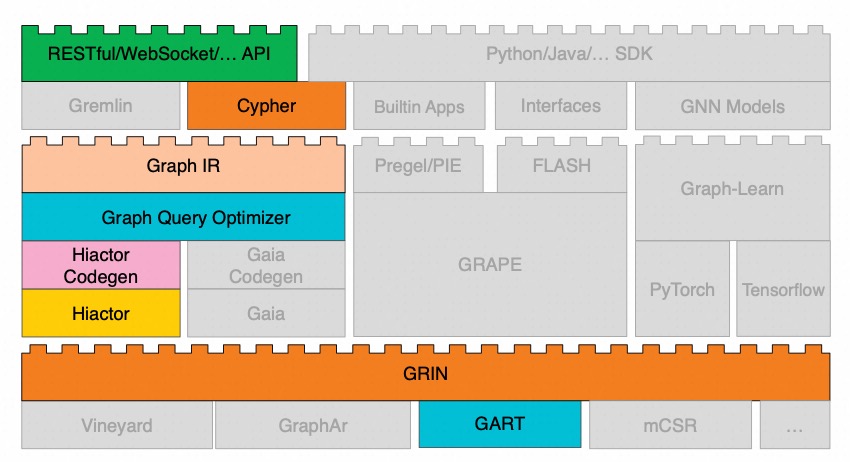
To achieve real-time fraud detection, we can select the components shown in the diagram to construct a graph computing system. Considering that order data is continuously arriving, we have chosen the GART component, which supports multi-version variable memory graph storage.
At the execution engine layer, since we need to handle a large volume of orders in a short time, the core metric we need to focus on is system throughput. Therefore, we have selected the Hiactor Codegen and Hiactor components, along with the GraphIR component and the Graph Query Optimizer component, to receive queries written in Cypher from the frontend layer.
With this deployment plan on real datasets, we can achieve performance exceeding 350,000 QPS.
Friendship Relationship Prediction
When e-commerce platforms make product recommendations, a very important strategy is to recommend products liked by a user’s friends. However, the friendship relationship data among users on e-commerce platforms is often incomplete, so it is necessary to predict whether a friendship exists between two users. Since graphs can naturally depict the relationships among users, this issue can also be transformed into a graph computing problem. Currently, the industry commonly uses graph neural networks to handle graph-based friendship relationship prediction tasks.
Based on e-commerce data, we can first construct a graph as shown in the diagram, where each vertex represents users, products, comments, etc., and edges represent friendships, purchases, comments, etc. In graph neural network models, such as those represented by the NCN algorithm, calculations like “common friends” need to be performed on the graph, as two users with many common friends are more likely to have a friendship.
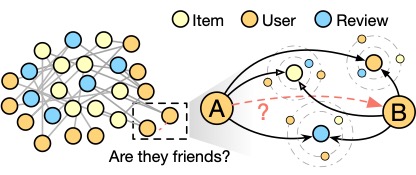
To deploy a system for friendship relationship prediction based on GraphScope Flex, we can select the components shown in the diagram from GraphScope Flex. In this setup, the Vineyard component in the storage layer models the data as a property graph and stores it in memory. The Graph-Learn component is responsible for calculating common friends, neighbor sampling, and other operations, while the PyTorch module is used for graph neural network inference. At the frontend layer, users can invoke the inference service through the Python SDK.
High Performance and Continuous Iteration
Thanks to the modular design of GraphScope Flex, it has achieved efficient performance across a variety of workloads. Notably, in the internationally recognized benchmark for transactional online query scenarios, LDBC-SNB, GraphScope Flex achieved a performance that surpasses the previous record holder by 2.6 times, securing the top position. We will also publish articles in the future to provide detailed information about the design of each module, so stay tuned!