图学习引擎#
GraphScope中的图学习引擎 (GLE) 是面向大规模图神经网络的研发和应用而设计的一款分布式框架。 它从实际问题出发,提炼和抽象了一套适合于当下图神经网络模型的编程范式, 并已经成功应用在阿里巴巴 内部的诸如搜索推荐、网络安全、知识图谱等众多场景。 GL注重可移植和可扩展,对于开发者更为友好,为了应对GNN在工业场景中的多样性和快速发展的需求。 基于GL,开发者可以实现一种GNN算法,或者面向实际场景定制化一种图算子,例如图采样。
接下来,我们通过一个入门教程介绍如何使用 GLE 来构建用户自己的CNN模型。
图学习模型#
图学习算法的实现目前主要有两种方式。第一种是直接以全图为计算对象, 原始的GCN,GAT等算法都是这种实现思路,一般会直接用邻接矩阵进行计算。 然而这种方法在大规模图上会消耗大量内存,导致无法高效训练甚至无法训练。 第二种思路是将全图分成若干子图,用深度学习里常用的批次训练方法进行训练, 每次训练一个子图,代表方法是GraphSAGE,FastGCN, GraphSAINT等。
GLE 主要面向超大规模图神经网络的开发。它由底层的一个图引擎和上层的 算法模型构成。图引擎分布式存储图的拓扑和属性信息并提供高效的图采样查询 接口,算法模型通过调用图采样和查询接口获取子图并进行计算。
GLE 提供了一个图学习算法的统一编程框架,支持常见图学习算法的开发,包括 GNNs, 知识图谱模型,图嵌入算法等,并且和主流的深度学习算法兼容,包括TensorFlow 和PyTorch。目前我们实现了基于TensorFlow的模型,基于PyTorch的模型正在开发中。
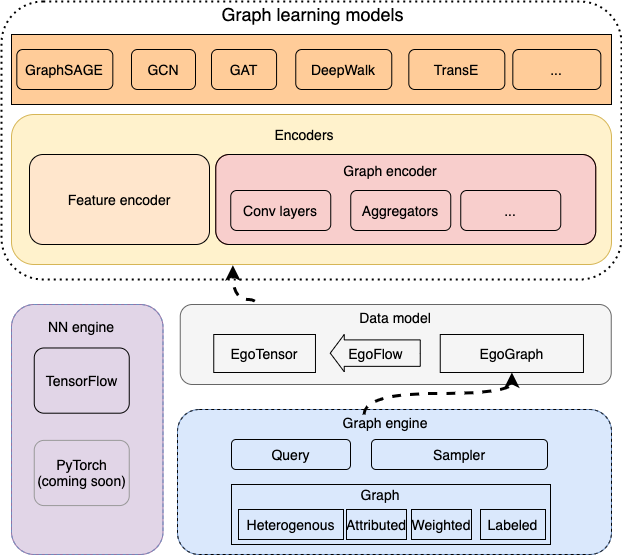
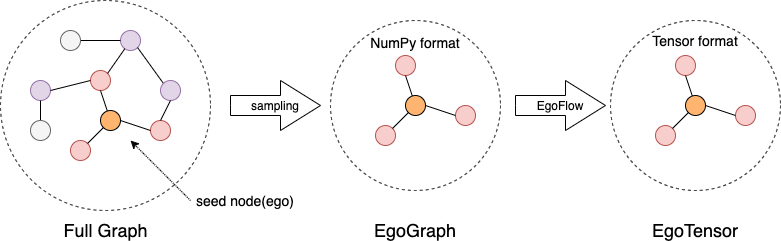
数据模型#
GLE 采用采样子图再计算的方式构建和训练模型。我们首先介绍一下基本的数据模型。
EgoGraph 是图学习算法编程的基本数据对象。它由一个batch的种子点或者边(称为’ego’)
以及他们的’感受野’(多跳邻居)组成。EgoGraph 由图采样和查询到的数据组成,我们实现
了常见的邻居采样、图遍历和负采样方法。
采样的数据组织成numpy格式的 EgoGraph 后根据不同的深度学习引擎转换成对应的tensor格式
EgoTensor,然后用``EgoFlow`` 管理 EgoGraph 到 EgoTensor 的转换,提供训练所需要的数据。
编码器#
所有的图学习模型可以抽象为使用编码器将 EgoTensor 编码成最终的点、边或者子图的
向量。GLE 首先利用特征编码器来编码原始的点和边上的特征,然后将特征编码器编码后的
原始向量用不同的图编码器进行编码,得到最终的输出。对于大多数GNN模型,图编码器
提供了如何聚合邻居信息到自身节点或者边的抽象,用不同的图卷积层实现。
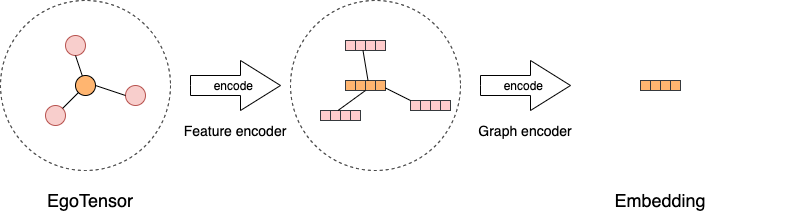
基于上面介绍的数据模型和编码器,我们可以简单快速地实现不同的图学习算法。在接下来一章里, 我们详细介绍了如何开发一个GNN模型。
自定义算法#
这篇文档我们将介绍如何用 GLE 提供的基本API配合深度学习引擎(如TensorFlow)来构建图学习算法。 我们以图神经网络里最流行的GCN模型做为示例来说明。
通常来说,实现一个算法需要下面四个步骤:
指定采样模式:用图采样、查询方法采样子图并组织成
EgoGraph。我们抽象了4个基本的函数,
sample_seed,positive_sample,negative_sample和receptive_fn。sample_seed用来遍历图数据产生Nodes或者Edges, 然后positive_sample以这些Nodes或者Edges为输入产生 训练的正样本。对于无监督学习negative_sample产生负样本。 GNNs需要聚合邻居信息, 我们抽象了receptive_fn来采样邻居。 最后将sample_seed产生的Nodes、Edges以及采样出的邻居组成EgoGraph。构建图数据流:使用
EgoFlow将EgoGraph转换为EgoTensor。GLE 算法模型基于类似TensorFlow的深度学习引擎构建。所以采样出的
EgoGraph``s 需要先转换成tensor格式 ``EgoTensor才能使用。我们抽象了EgoFlow来封装这一转换过程。EgoFlow可以产生一个迭代器来进行批次训练。定义编码器:使用
EgoGraph编码器和特征编码器来编码EgoTensor。 得到EgoTensor后,我们首先将原始的点、边特征用一些常见特征编码器编码成原始向量, 做为GNNs模型的特征输入。然后用图编码器处理EgoTensor,将邻居节点特征进行汇聚并 和自身特征进行组合,得到最后的点或者边的向量。编写损失函数和训练过程:选择适当的损失函数,并编写训练过程。
GLE 内置了一些常见的损失函数和优化器,并对训练过程进行了封装,同时支持单机和分布式训练。 你也可以自定义损失函数、优化器和训练过程。
下面我们按照上面介绍的4个步骤来介绍如何实现一个GCN模型。
采样#
我们使用Cora数据集以点分类任务做为示例。我们提供了一个简单的数据转换脚本 cora.py 来
将原始Cora转换成 GLE 需要的格式。运行完这个脚本后你可以得到下面5个文件
node_table, edge_table_with_self_loop, train_table, val_table and test_table。
分别是点表、边表以及用来区分训练、验证和测试集的点表。
然后可以用下面代码来构建图:
import graphlearn as gle
g = gle.Graph()\
.node(dataset_folder + "node_table", node_type=node_type,
decoder=gle.Decoder(labeled=True,
attr_types=["float"] * 1433,
attr_delimiter=":"))\
.edge(dataset_folder + "edge_table_with_self_loop",
edge_type=(node_type, node_type, edge_type),
decoder=gle.Decoder(weighted=True), directed=False)\
.node(dataset_folder + "train_table", node_type="train",
decoder=gle.Decoder(weighted=True))\
.node(dataset_folder + "val_table", node_type="val",
decoder=gle.Decoder(weighted=True))\
.node(dataset_folder + "test_table", node_type="test",
decoder=gle.Decoder(weighted=True))
使用 g.init() 后这段代码会将图加载进内存:
class GCN(gle.LearningBasedModel):
def __init__(self,
graph,
output_dim,
features_num,
batch_size,
categorical_attrs_desc='',
hidden_dim=16,
hops_num=2,):
self.graph = graph
self.batch_size = batch_size
GCN模型继承自基本的学习模型类 LearningBasedModel,只需要重写基类的采样,
模型构建等方法就可以完成GCN的构建。
class GCN(gle.LearningBasedModel):
# ...
def _sample_seed(self):
return self.graph.V('train').batch(self.batch_size).values()
def _positive_sample(self, t):
return gle.Edges(t.ids, self.node_type,
t.ids, self.node_type,
self.edge_type, graph=self.graph)
def _receptive_fn(self, nodes):
return self.graph.V(nodes.type, feed=nodes).alias('v') \
.outV(self.edge_type).sample().by('full').alias('v1') \
.outV(self.edge_type).sample().by('full').alias('v2') \
.emit(lambda x: gle.EgoGraph(x['v'], [ag.Layer(nodes=x['v1']), ag.Layer(nodes=x['v2'])]))
前两个函数用来采样种子节点和正样本,_receptive_fn 采样邻居并组织 EgoGraph,
outV 回一跳邻居,因此上面代码是采样二跳邻居。这里可以选择不同的邻居采样方法,
对于原始GCN来说因为要获得每个点的所有邻居,因此选择 'full'。采样完后将结果组织
成 EgoGraph 返回。
图数据流#
在 build 函数里我们使用封装的 EgoFlow 来把 EgoGraph 转换成对应的 EgoTensor,
EgoFlow 包含一个数据流迭代器和若干 EgoTensor。
class GCN(gle.LearningBasedModel):
def build(self):
ego_flow = gle.EgoFlow(self._sample_seed,
self._positive_sample,
self._receptive_fn,
self.src_ego_spec)
iterator = ego_flow.iterator
pos_src_ego_tensor = ego_flow.pos_src_ego_tensor
# ...
你可以从 EgoFlow 获取和前面 EgoGraph 对应的 EgoTensor。
模型#
接下来,首先使用特征编码器来编码原始特征。这里我们使用 IdentityEncoder,即返回自身即可,因为
Cora的特征已经是处理过的向量格式了。对于既有离散特征由于连续特征的情况,可以使用 WideNDeepEncoder。
更多encoder请参考 feature encoder。
然后用 GCNConv 层构建图编码器,GCN每个节点采样全部邻居,邻居以稀疏格式组织,所以这里使用
SparseEgoGraphEncoder, 邻居对齐的模型可以参考GraphSAGE的实现。
class GCN(gle.LearningBasedModel):
def _encoders(self):
depth = self.hops_num
feature_encoders = [gle.encoders.IdentityEncoder()] * (depth + 1)
conv_layers = []
# for input layer
conv_layers.append(gle.layers.GCNConv(self.hidden_dim))
# for hidden layer
for i in range(1, depth - 1):
conv_layers.append(gle.layers.GCNConv(self.hidden_dim))
# for output layer
conv_layers.append(gle.layers.GCNConv(self.output_dim, act=None))
encoder = gle.encoders.SparseEgoGraphEncoder(feature_encoders,
conv_layers)
return {"src": encoder, "edge": None, "dst": None}
损失函数和训练过程#
对于Cora点分类模型,我们选择对应的TensorFlow里的分类损失函数即可。
然后在 build 函数里将编码器和损失函数组织起来,最终返回一个数据迭代器和损失函数。
class GCN(gle.LearningBasedModel):
# ...
def _supervised_loss(self, emb, label):
return tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(emb, label))
def build(self):
ego_flow = gle.EgoFlow(self._sample_seed,
self._positive_sample,
self._receptive_fn,
self.src_ego_spec,
full_graph_mode=self.full_graph_mode)
iterator = ego_flow.iterator
pos_src_ego_tensor = ego_flow.pos_src_ego_tensor
src_emb = self.encoders['src'].encode(pos_src_ego_tensor)
labels = pos_src_ego_tensor.src.labels
loss = self._supervised_loss(src_emb, labels)
return loss, iterator
接着使用封装的单机训练过程 LocalTFTrainer 来进行训练。
def train(config, graph)
def model_fn():
return GCN(graph,
config['class_num'],
config['features_num'],
config['batch_size'],
...)
trainer = gle.LocalTFTrainer(model_fn, epoch=200)
trainer.train()
def main():
config = {...}
g = load_graph(config)
g.init(server_id=0, server_count=1, tracker='../../data/')
train(config, g)
这样就完成了一个GCN模型的编写。完整代码请参考 GCN example 目录。
我们实现了GCN, GAT, GraphSage, DeepWalk, LINE, TransE, Bipartite GraphSage, sample-based GCN and GAT等模型,你可以参考相似的模型代码做为开始。