GAIA Deep Dive: Bounded-Memory Execution and Early-Stop Optimization for Efficient Graph Traversal at Scale
 Last time, we presented an overview of the GAIA engine for scaling Gremlin for large distributed graphs. In contrast to other, existing batch-oriented big graph processing systems, such as Google Pregel, Apache Giraph, GraphLab PowerGraph, and Apache Spark GraphX, GAIA focuses on low-latency graph traversal at scale. Achieving this goal requires a different distributed infrastructure. Today, we continue to explain why with highlighting two unique and key features of GAIA.
Last time, we presented an overview of the GAIA engine for scaling Gremlin for large distributed graphs. In contrast to other, existing batch-oriented big graph processing systems, such as Google Pregel, Apache Giraph, GraphLab PowerGraph, and Apache Spark GraphX, GAIA focuses on low-latency graph traversal at scale. Achieving this goal requires a different distributed infrastructure. Today, we continue to explain why with highlighting two unique and key features of GAIA.
Bounded-Memory Execution
Graph traversal can produce paths of arbitrary length, leading to memory usage growing exponentially with the number of hops. Although it is very common for Gremlin queries to terminate with a top-k constraint and/or aggregate operation, such an explosion of intermediate results can often lead to memory crisis, especially in an interactive environment with limited memory configuration.
On the other hand, the traversal strategies can greatly impact the memory usage. There are two typical traversal strategies, namely (breadth-first-search) BFS-like traversal and (depth-like-search) DFS-like traversal. BFS-like traversal can better utilize parallelism, while it may produce data all at once that drives high the memory usage. On the contrary, DFS-like traversal tends to consume much less memory, while it may suffer from low parallelism.
To ensure bounded-memory execution without sacrificing performance (parallelism), GAIA employs dynamic scheduling for executing each Gremlin operator. GAIA packs a segment of consecutive data entries in an input stream into a single batch, and such a batch constitutes the finest data granularity for communication and computation. A task can be logically viewed as the combination of an operator and a batch of data entries to be computed. GAIA dynamically creates such tasks corresponding to each operator when there is one or more batches available from all its inputs, and maintains all the tasks in a same scheduling queue to share resources.
Furthermore, GAIA can schedule tasks with priorities according to the occurrence order of its corresponding operators in a Gremlin query. Specifically, it can schedule the operators that appear first with higher priority for a BFS-like traversal, and prioritize those that appear last to follow a DFS-like traversal. To balance the memory usage with the performance (parallelism), GAIA by default adopts a hybrid traversal strategy, that is, it uses BFS-prioritized scheduling as it has better opportunities for parallelization, and automatically switches to DFS-prioritized in case that the current operator arrives at the memory bound.
To validate the hypothesis, we use the following cycle-detection query as an example to compare GAIA with the current MaxGraph release in GraphScope without memory control.
g.V([vertices]).as('a').repeat(out().simplePath())
.times(k-1)
.out().where(as('a'))
.path().limit(n)
The above cycle-detection query starts from m (default 10) vertices in V, it traverses from V via at most k (default 3) hops, and returns at most n cycles found along the traversal.
We generate large LDBC data sets with scale factor 30. The generated LDBC data sets which have 89 million vertices and 541 million edges would be used for the following experiments. In this experiment, we set memory upper bound of GAIA to 256MB, and compare with MaxGraph. For this query, We vary the number of start vertices, set k to 3 and set result limit to infinity. We report both the query latency and max memory consumption in the following.
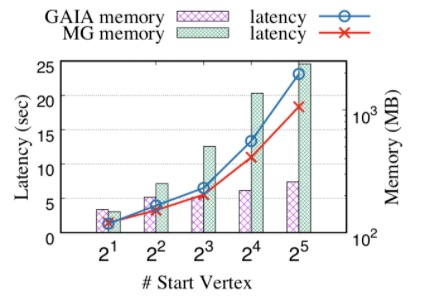
As the figure shows, GAIA achieves much lower memory usage (up to 9× memory saving) comparing to MaxGraph as well as comparable performance. We can see the actual memory usage of all cases in GAIA is very close to the bounded value 256MB. This expriment shows that GAIA ensure bounded-memory execution without sacrificing performance (parallelism) thanks to powerful dynamic scheduling.
Early-Stop Optimization
Traversing all candidate paths fully is often unnecessary, especially for interactive queries with dynamic conditions running on diverse input graphs. For example, in the above query, only the first k results are needed. This leads to an interesting tradeoff between parallel traversal and wasted computation, as further illustrated in the following figure.
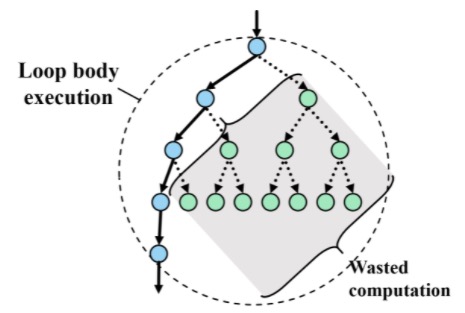
The figure shows an example run of the query with k=1. The circle denotes the traversal specified by the repeat-loop. Assume we have enough computation resource (CPU cores), the paths can be explored in a fully parallel fashion. However, once a 4-hop path is found, all the remaining parallel traversal will be no longer required.
For real-world queries on large graph data, such wasted computation can be hidden deeply in nested traversals (e.g., a predicate that can be evaluated early from partial inputs) and significantly impact query performance. While avoiding such wastage is straightforward in a sequential implementation, it is challenging to do so for a fully-parallel execution.
To minimize such wastage, GAIA tracks data dependencies dynamically at runtime. When enough results are collected, the system automatically creates a cancellation token that is sent backward along input streams to its upstream operators within the same execution context. The token serves as a signal for receiving operators to clear any unsent output data and immediately cancel any on-going computation for the particular output stream. Such cancellation notification is implemented at a system level by GAIA. Below, we continue to use the cycle-detection query as a running example to demonstrate that such early-stop optimization can significantly improve query performance.
In this experiment, we vary the number of result limit and report the latency of GAIA and MaxGraph.
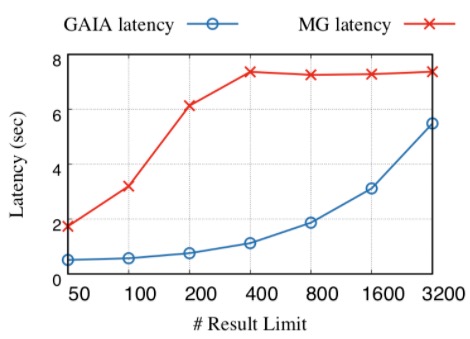
The figure shows that GAIA outpeforms MaxGraph in all cases thanks to the ablility of cancelling wasted computation. GAIA achieves 4.5× better performance in average, up to 8.1×. Even the number of limit results is close to the complete query result, GAIA can also show better performance due to the fine-grained early-stop mechanism. Note that MaxGraph can also achieve low latency when the limit size is small (50), this is because a naive early-stop is implemented in MaxGraph to cancel the job from source operator to the end when already collected needed results. But the performance degrades rapidly when the limit size become larger due to coarse-grained job cancelling in MaxGraph.
Scalability
Finally, we study the scalability while running the same query as above. This is to prove that both features do not introduce additional overheads that impact performance/scalability of GAIA.
In this experiment, we set the query result limit to infinity and vary the number of computing threads to show the scale-up performance of GAIA. We test the scalability using different size of queries by varying the number of start vertices.
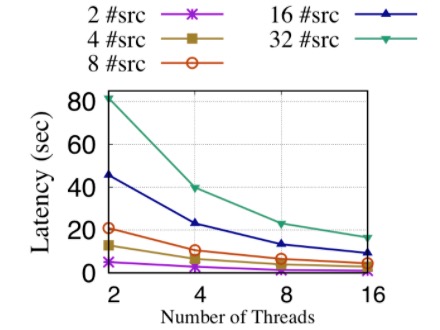
As we can see from the above figure, GAIA has linear scalability in all type (both large and small) of queries. It shows that new features such as dynamic scheduling do not hurt the scalability of GAIA.
Conclusion
Diverse and irregular graph data and algorithms impose significant challenges in efficient distributed and parallel execution. Implementation choices can have a huge impact on system performance and memory requirements. GAIA is the first engine to support efficient graph traversal at scale that enables bounded-memory execution with minimum wastage. It will be included as an experimental feature in the coming release of GraphScope v0.6.0. We welcome community feedback!