Getting Started with GraphAr: Standardized Graph Storage File Format
 GraphAr is an open source, standard data file format for graph data storage and retrieval. It defines a standardized file format for graph data, and provides a set of interfaces for generating, accessing, and transforming these formatted files.
This post is a quick guide that explains how to work with GraphAr, using the C++ SDK it provides.
GraphAr is an open source, standard data file format for graph data storage and retrieval. It defines a standardized file format for graph data, and provides a set of interfaces for generating, accessing, and transforming these formatted files.
This post is a quick guide that explains how to work with GraphAr, using the C++ SDK it provides.
What is GraphAr?
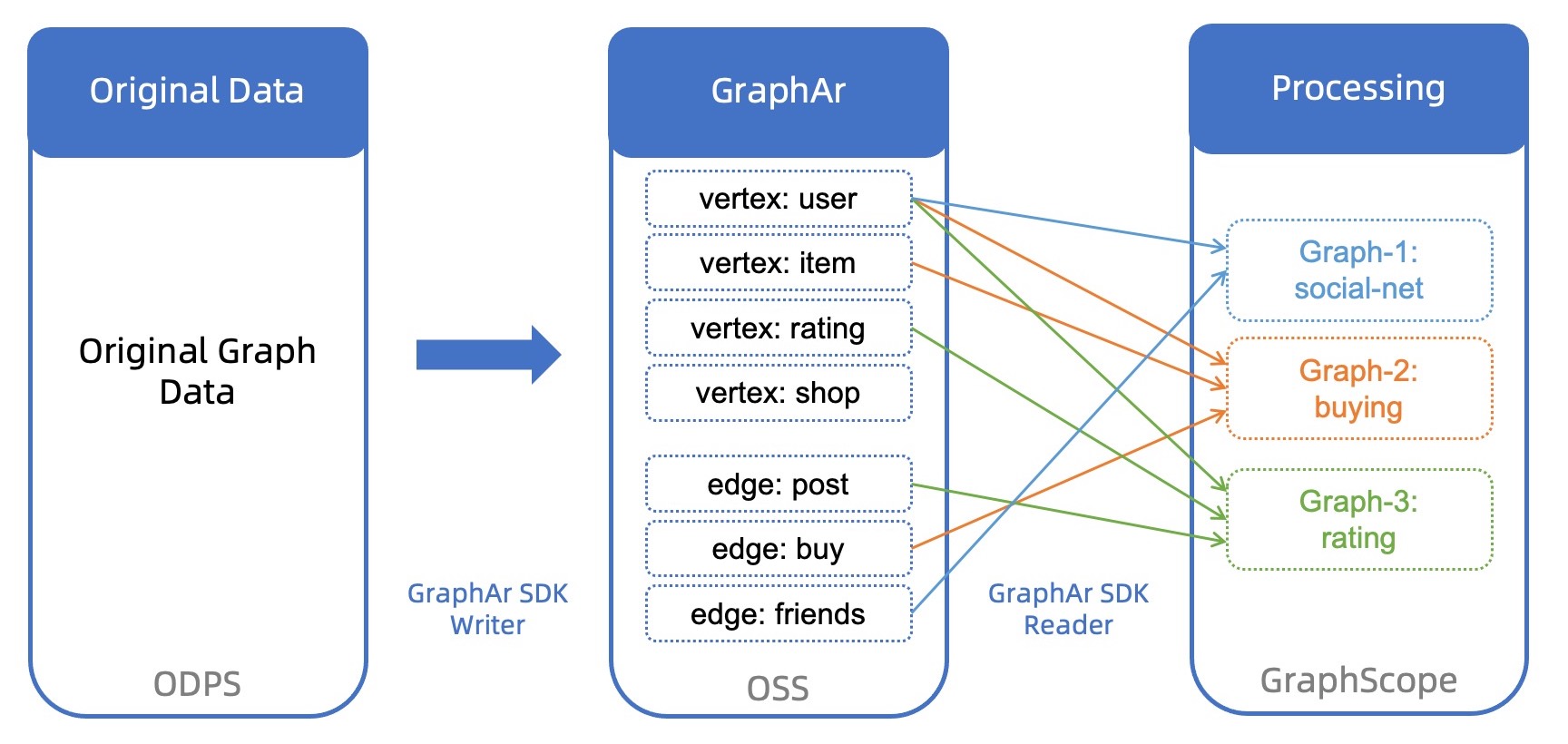
GraphAr (Graph Archive, abbreviated as GAR) defines a standardized, system-independent file format for graph data and provides a set of interfaces for generating, accessing, and converting these formatted files. GraphAr can help various graph computing applications or existing systems to conveniently build and access graph data. It can be used as a direct data source for graph computing applications, as well as for importing/exporting and persistently storing graph data, reducing the overhead of collaboration between various graph systems. The following figure shows the scenario of using GraphAr as a graph data archiving format in typical business: with GraphAr, users can quickly assemble a graph with the required vertex and edge data for subsequent processing, such as GraphScope graph analysis tasks.
GraphAr C++ uses CMake as a build configuration system. To install the GraphAr C++ SDK from source code, you need to install the following dependencies:
- A C++17-enabled compiler. On Linux, gcc 7.1 and higher should be sufficient. For MacOS, at least clang 5 is required
- CMake 3.5 or higher
- On Linux and macOS, make build utilities
- curl-devel with SSL (Linux) or curl (macOS), for s3 filesystem support
To set up the environment and compile/install the GraphAr C++ SDK from source code, you can follow these steps:
# download the source code
$ git clone https://github.com/alibaba/GraphAr.git
# update submodule
$ git submodule update --init
# compile
$ cd GraphAr/cpp
$ mkdir build-release
$ cd build-release
$ cmake ..
$ make -j$(nproc)
# install GraphAr C++ SDK
$ sudo make install
More details about compiling and installing GraphAr C++ SDK can be found in the documentation.
Defining Information Files
GraphAr uses a group of Yaml files to save the meta information for a graph. The graph information file defines the most basic information of a graph includes its name, the root directory path of the data files, the vertex information and edge information files it contains, and the version of GraphAr. The vertex information file and edge information file define the information of the vertex and edge types in the graph, respectively. For example, the file “ldbc_sample.graph.yml” defines an example graph named “ldbc_sample”, which includes one type of vertices (“person”) and one type of edges (“person knows person”). The three information files are shown below:
- ldbc_sample.graph.yml
name: ldbc_sample
vertices:
- person.vertex.yml
edges:
- person_knows_person.edge.yml
version: gar/v1
- person.vertex.yml
label: person
chunk_size: 100
prefix: vertex/person/
property_groups:
- properties:
- name: id
data_type: int64
is_primary: true
file_type: parquet
- properties:
- name: firstName
data_type: string
is_primary: false
- name: lastName
data_type: string
is_primary: false
- name: gender
data_type: string
is_primary: false
file_type: parquet
version: gar/v1
- person_knows_person.edge.yml
src_label: person
edge_label: knows
dst_label: person
chunk_size: 1024
src_chunk_size: 100
dst_chunk_size: 100
directed: false
prefix: edge/person_knows_person/
adj_lists:
- ordered: true
aligned_by: src
file_type: parquet
property_groups:
- properties:
- name: creationDate
data_type: string
is_primary: false
file_type: parquet
version: gar/v1
GraphAr stores the actual graph data in files in the specified directory, following the format defined in the information files. Each data chunk is stored in a separate file, which can be in the ORC, Parquet, or CSV format. The data files for the graphs described in the three Yaml files can be found in the GraphAr test data. For more information on the definition of the GraphAr file format, please refer to the GraphAr File Format Introduction.
Using GraphAr C++ SDK
Construct Information
The metadata of a graph can be constructed easily through reading the already existed information files, as the following code illustrates:
#include "gar/graph_info.h"
// construct graph info from yaml file
std::string path = "/tesing/ldbc_sample.graph.yml"; // yaml file path
auto graph_info = GraphArchive::GraphInfo::Load(path).value();
// get vertex info
auto maybe_vertex_info = graph_info.GetVertexInfo("person");
if (maybe_vertex_info.status().ok())) {
auto vertex_info = maybe_vertex_info.value();
// ...
}
// get edge info
auto maybe_edge_info = graph_info.GetEdgeInfo("person", "knows", "person");
if (maybe_edge_info.status().ok())) {
auto edge_info = maybe_vertex_info.value();
// ...
}
Reading from GraphAr
GraphAr supports the flexible reading of graph data, e.g., allowing to read data of a single vertex, a vertex chunk, or all vertices with a specific label. In addition, necessary property groups can be selected to read and avoid reading all properties from the files. Furthermore, it provides convenient and flexible access to adjList, offset and property chunks for edges.
As a simple case, the following example shows how to read all vertices with label “person” of the graph defined by “graph_info” and output the values of “id” and “firstName” for each vertex.
#include "gar/graph.h"
auto& vertices = GraphArchive::ConstructVerticesCollection(graph_info, "person").value();
for (auto it = vertices.begin(); it != vertices.end(); ++it) {
auto vertex = *it;
std::cout << "firstName= "
<< vertex.property<std::string>("firstName").value() << std::endl;
}
The next example reads all edges with label “person_knows_person” from the above graph and outputs the end vertices for each edge.
auto expect = GraphArchive::ConstructEdgesCollection(
graph_info, "person", "konws" "person",
GraphArchive::AdjListType::ordered_by_source)
.value();
auto& edges = std::get<GraphArchive::EdgesCollection<
GraphArchive::AdjListType::ordered_by_source>>(expect.value());
auto vertex_index = 0; // the index of the vertex whose edges are to be read
auto it = edges.first_src(vertex_index); // get the iterator of the first edge
if (it != edges.end()) {
do {
GraphArchive::IdType src = it.source(), dst = it.destination();
std::cout << src << ' ' << dst << std::endl;
} while (it.next_src()); // get the next edge
}
Writing to GraphAr
As same with the readers, the GraphAr writers provide different-level methods to output the graph data in memory into GraphAr files.
As the simplest cases, the example below adds vertices to VerticesBuilder and then dumps the data to files; it also adds edges to EdgesBuilder and then dumps them.
#include "gar/writer/edges_builder.h"
#include "gar/writer/vertices_builder.h"
auto prefix = "/tesing/"; // the root directory of the graph data
GraphArchive::builder::VerticesBuilder v_builder(vertex_info, prefix);
GraphArchive::builder::Vertex v;
v.AddProperty("id", 933);
v.AddProperty("firstName", "Alice");
v_builder.AddVertex(v); // add a vertex
// add other vertices...
v_builder.Dump(); // write out to GraphAr
GraphArchive::builder::EdgesBuilder e_builder(edge_info, prefix,
GraphArchive::AdjListType::ordered_by_source,
vertices_num);
GraphArchive::builder::Edge e(0, 3);
e.AddProperty("creationDate", "2011-07-20T20:02:04.233+0000");
e_builder.AddEdge(e); // add an edge
// add other edges...
e_builder.Dump(); // write out to GraphAr
A PageRank Example
In addition to serving as a standardized archive format for graph data, GraphAr has another important use case: it can act as a direct data source, supporting the implementation of various out-of-core graph algorithms through its file access interface. This allows for the analysis and processing of large-scale graph data using limited memory and computational resources on a single machine. The GraphAr code repository already provides implementations for several typical out-of-core graph algorithms, including PageRank, BFS, and weakly connected components.
Taking PageRank as an example, a single-machine out-of-core algorithm implemented with GraphAr would first read the yaml file to obtain the graph’s metadata. Then, VerticesCollection and EdgesCollection are constructed to facilitate accessing the graph data. Subsequently, the edge data is loaded from the GraphAr disk file in a streaming fashion using an iterator and used to update the PageRank results for each vertex in memory. Finally, we can extend the metadata of vertices of the original “person” type to include a new attribute named “pagerank” and use VerticesBuilder to write the computation results into a new GraphAr data file. The core computation portion of the PageRank algorithm can be seen in the sample code below, and the complete code can be found in the GraphAr example code.
auto it_begin = edges.begin(), it_end = edges.end();
// max_iters: the number of iterations
for (int iter = 0; iter < max_iters; iter++) {
std::cout << "iter " << iter << std::endl;
// iterate over all edges
for (auto it = it_begin; it != it_end; ++it) {
GAR_NAMESPACE::IdType src = it.source(), dst = it.destination();
// using source vertex to update destination vertex
pr_next[dst] += pr_curr[src] / out_degree[src];
}
// iterate over all vertices and update PageRank value
for (GAR_NAMESPACE::IdType i = 0; i < num_vertices; i++) {
pr_next[i] = damping * pr_next[i] +
(1 - damping) * (1 / static_cast<double>(num_vertices));
if (out_degree[i] == 0)
pr_next[i] += damping * pr_curr[i];
pr_curr[i] = pr_next[i];
pr_next[i] = 0;
}
}
Please refer to more examples to learn about the other available case studies utilizing GraphAr.