GraphScope's Perspective Sharing at the SIGMOD 2024 Panel: The Future of Graph Analytics
 From June 9th to June 15th, 2024, SIGMOD 2024 was held in Santiago, Chile.
Graph computing remains a hot topic at this conference, and it is also the area that received the most paper submissions.
SIGMOD 2024 organized a panel discussion on graph computation titled “The Future of Graph Analytics”.
From June 9th to June 15th, 2024, SIGMOD 2024 was held in Santiago, Chile.
Graph computing remains a hot topic at this conference, and it is also the area that received the most paper submissions.
SIGMOD 2024 organized a panel discussion on graph computation titled “The Future of Graph Analytics”.
This panel invited six well-known individuals from the academic and industrial sectors of graph computing, including Professor Angela Bonifati from Lyon 1 University, Professor M. Tamer Özsu from the University of Waterloo, Yuanyuan Tian, a Principal Scientist Manager from Microsoft, Hannes Voigt, a Staff Engineer from Neo4j, Professor Wenjie Zhang from the University of New South Wales, and Dr. Wenyuan Yu, the person in charge of GraphScope.
Graph computing plays an important role in real-world business scenarios, and various graph computing systems are emerging one after another. Nowadays, the types of graph computing tasks are becoming more diverse, and they form complex workflows together with other task types, such as machine learning and Large Language Model (LLM) tasks. This also leads to new discussions and considerations regarding graph computing. The panel discussed the following six issues, and Dr. Wenyuan Yu shared GraphScope’s perspectives on these matters.
Q: Given the varied types of graph computations and the widespread use of graph query languages (e.g., Cypher, GQL), do we need new and more expressive query languages?
A: Considering the diverse and extensive applications of graphs, there is still a need for new query languages. However, languages with strong expressive power often come with increased complexity, so finding a balance between complexity and expressiveness is essential. The computing patterns for different types of graph computing tasks, such as pattern matching, graph analysis, and graph neural networks, exhibit both significant differences and some overlaps, making the balance challenging to achieve.
Over the past two years, the development of Large Language Models (LLMs) has inspired the idea that natural language processing enhanced by LLMs could play a vital role in simplifying complex queries and reducing the learning curve for users.
Q: In many cases, graph data originates from OLTP systems, while graph analysis is a typical OLAP operation. Do we, therefore, need to build an HTAP system for graph analysis?
A: Regarding the necessity of building an HTAP system for graph analysis, we believe it is essential. However, it is not necessary to process OLTP and OLAP tasks within the same system simultaneously. On the one hand, users’ core businesses often rely on very mature OLTP systems, such as relational databases, and it may be challenging for users to migrate their core businesses to a new system simply to add OLAP capabilities for graph analysis. On the other hand, performing OLAP tasks directly on the storage systems designed for OLTP can be highly inefficient.
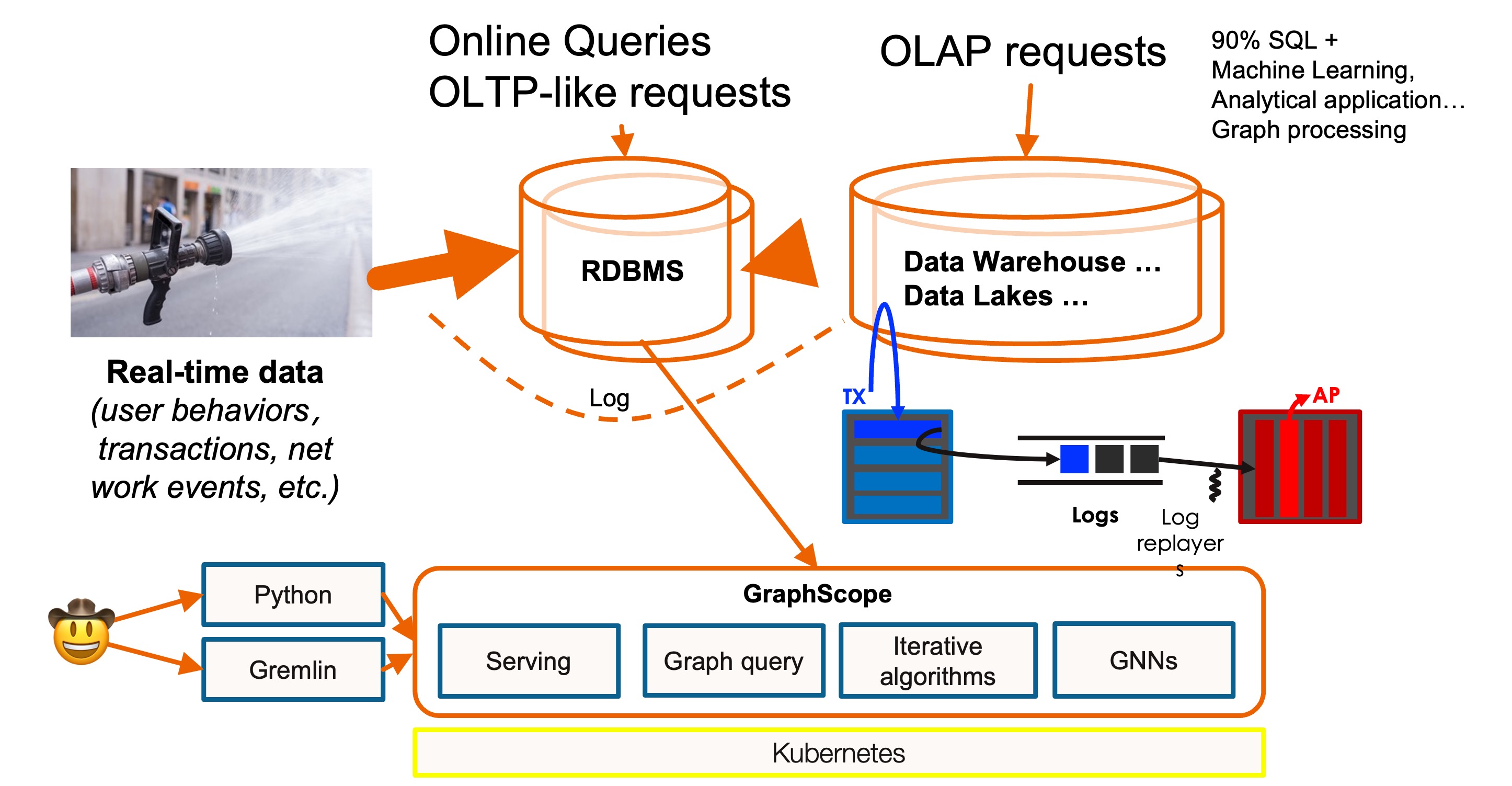
To address this, we developed and open-sourced a system called GART. Its core architecture, as depicted in the diagram above, captures changes from OLTP systems (such as binlog from MySQL) and synchronizes these changes in real-time. The changes to table data in OLTP systems correspond to operations of adding, deleting, or modifying vertices and edges in graph data. GART has also been designed with efficient mutable graph storage and is integrated with the GraphScope’s graph analytical engine GAE and the graph interactive engine GIE. This allows users to intuitively express queries with graph semantics and achieve efficient execution on GraphScope’s engine. Consequently, graph HTAP capabilities are achieved without any modifications to the existing OLTP system.
Q: Currently, benchmarks for graph analysis focus more on system performance metrics such as the execution of algorithms. Should we also focus on other metrics?
A: In addition to performance metrics, we believe that benchmarks for graph analysis should consider two additional aspects. Firstly, concerning the graphs themselves, it is important to increase the diversity of graph algorithms and datasets. The range of graph algorithms should extend beyond well-known examples like PageRank and Shortest Path. New algorithms need to exhibit a variety of graph access patterns and computational characteristics. In addition, benchmarks should include varied types of datasets beyond just social network datasets. Secondly, when evaluating a system, we should assess the ease with which an algorithm can be implemented within that system, as this reflects the expressive power of the system’s interface. In this context, we have collaborated with external universities to propose a new benchmark for graph analysis.
Moreover, graph computations may represent only a small component of a complex workflow. Therefore, when testing a system, it is insufficient to just consider the execution time of a particular algorithm; we should also evaluate the time required for the system to load the graph from common file formats and export the results in other formats.
Q: In many cases, a complete graph computation task includes multiple types of sub-tasks. So, is one graph storage sufficient? In this case, do we need multiple graph storages?
A: Regarding whether multiple graph storages are needed, we believe they are necessary. Currently, various graph storages are designed for different scenarios and optimization objectives, and it is difficult to have a “one size fits all” solution. However, the existence of multiple storages means that when a task requires the use of multiple graph computing systems, data exchanges must be made between different systems to enable interfacing. To address this issue, GraphScope has taken the following two steps.
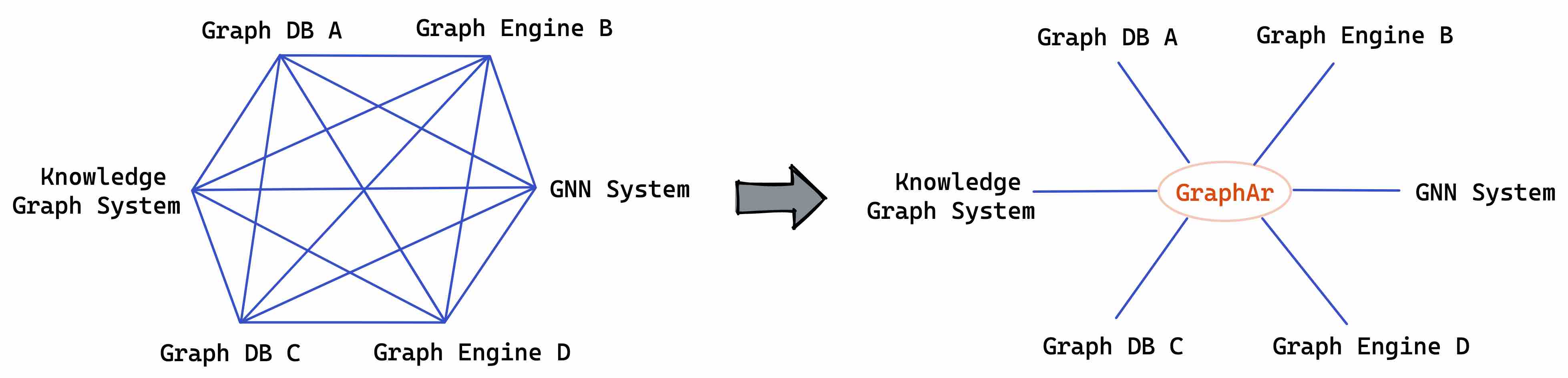
First, we designed a standardized graph storage file format, GraphAr, which defines a set of computing/storage system-independent file formats for graph data and provides a series of interfaces to generate, access, and convert these formatted files. As illustrated in the diagram below, GraphAr aims to solve the problem of data import/export and mutual access between various graph computing systems. GraphAr is now an Apache Incubator project and is actively promoting integration with mainstream graph systems in the industry.
On the other hand, we designed GRIN, a unified graph access interface, which defines a series of standardized interfaces for accessing graph data. Storages must implement these interface methods, and computing engines only need to use these interfaces to execute operators, thereby facilitating easy docking between different engines and storages.
Q: In a complex workflow, graph analysis may be just one component, alongside data analysis, machine learning, LLMs, and other types of tasks. In this scenario, do we need new APIs/DSLs to facilitate interaction between graph-related tasks and other tasks?
A: This question should be considered from two perspectives. On one hand, graphs are adept at intuitively expressing relationships between entities, which allows graph data to be utilized as part of knowledge graphs within RAG (Retrieval-Augmented Generation), interacting seamlessly with LLMs. Additionally, graph neural networks, which represent a fundamental aspect of machine learning, naturally integrate graph tasks with machine learning tasks.
On the other hand, the input and output formats of tasks involving graphs differ from those of tasks involving LLMs. To enable seamless interoperability between graph computation tasks and LLM tasks, we may need to consider the development of an ETL (Extract, Transform, Load) DSL in the future. Such a DSL would assist in resolving data alignment challenges that arise when integrating different types of tasks.
Q: In some scenarios, graph data is not static but constantly changing. What are the expectations for dynamic, incremental, and stream graph analysis operations?
A: For dynamic graph scenarios, we believe that compared to static graphs, the applications may be more diverse. The current hot topics in dynamic graph research include dynamic, incremental, and stream graph processing, with complex application scenarios requiring the integration of these technologies or even the advancement beyond current capabilities. To apply dynamic graphs effectively to real-world scenarios, we need to work on the following aspects:
- In terms of storage, efficient dynamic/stream graph storage capabilities are essential. These capabilities should not only support graph update operations efficiently but also provide efficient graph data access interfaces.
- Concerning graph algorithms, it is necessary to research incremental graph algorithms and explore the use of previously computed results to efficiently calculate the required outcomes on newly updated graphs.
- The time dimension is an essential aspect of dynamic graphs, and we need to enhance support for time-series graphs in our analysis operations.