Overview¶
GraphScope Interactive is a specialized construction of GraphScope Flex, designed to handle concurrent graph queries at an impressive speed. Its primary goal is to process as many queries as possible within a given timeframe, emphasizing a high query throughput rate. To quickly get started with GraphScope Interactive, please refer to the guideline on the Getting started.
A Solid Foundation¶
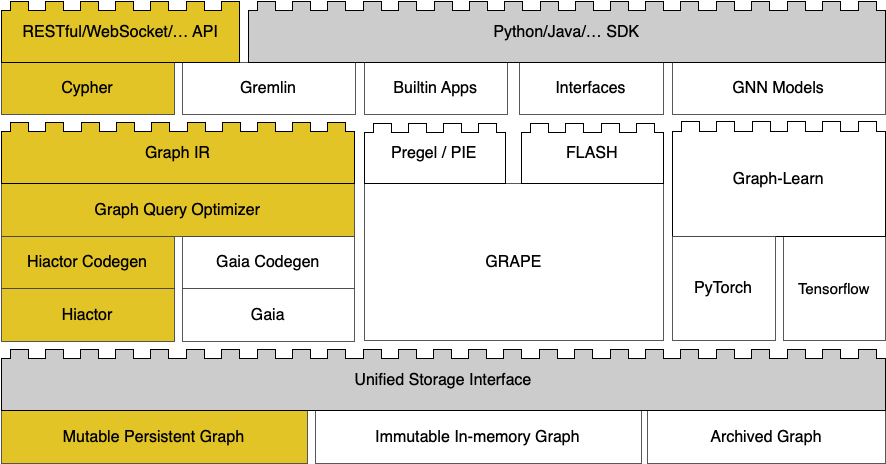
GraphScope Interactive in Flex¶
GraphScope Interactive stands on the shoulders of two pivotal pillars:
GraphScope Flex: GraphScope Flex is a new architecture of GraphScope that provides a solid foundation for GraphScope Interactive. It is designed to handle high-QPS (Queries Per Second) scenarios, making it an ideal base for the high-throughput demands of GraphScope Interactive.
Record-Breaking Benchmarking Results: GraphScope Interactive is built upon the record-breaking LDBC SNB Interactive benchmarking results, which has achieved a throughput of 33,180.87 ops/s for the benchmarking, making it one of the most efficient systems for graph query processing.
Key Features¶
GraphScope Interactive boasts several key features:
Exceptional Query Throughput: As highlighted, GraphScope Interactive’s foundation is laid on benchmarking triumphs, enabling it to process tens of thousands of queries swiftly.
Versatility in Language Support: GraphScope Interactive supports the Neo4j Cypher Query language. Cypher can also be used for crafting stored procedures. For those who prefer a more comprehensive approach, C++ programming is also supported for stored procedure development.
Future-Ready Expansion Capabilities: Drawing from the prowess of GraphScope Flex, GraphScope Interactive is primed for adaptability:
Support for Multiple Query Languages: In the near future, GraphScope Interactive will extend its language support to GQL, further enhancing its versatility.
Scalability: GraphScope Interactive possesses the potential for distributed processing. This means it can be expanded with few effort to handle larger-scale graphs, ensuring it remains effective as your data grows.
Massive Graph Support: To enhance system throughput and query performance, we store all graph data in memory by default. However, when encountering graph data too large to fit entirely in memory, we offload excess data to disk storage. This approach, while effectively handling massive-scale graph data, may result in reduced throughput. Moving forward, we aim to adopt a master-slave architecture designed to enhance concurrent querying performance. This will be achieved by distributing the workload across multiple machines, thereby optimizing resource utilization to improve throughput.
Property Graph Model and Graph Queries¶
GraphScope Interactive supports the property graph model, which allows for the representation of complex structures in an intuitive manner. It also supports various types of graph queries, including:
Traversal Query: This type of query involves traversing the graph from a set of source vertices while satisfying constraints on the vertices and edges that the traversal passes. It typically accesses a small portion of the graph rather than the whole graph.
Pattern Matching: Given a pattern that is a small graph, pattern matching aims to compute all occurrences of the pattern in the graph. It often involves relational operations to project, order, and group the matched instances.
The Cypher Query Language¶
GraphScope Interactive supports Cypher, a graph query language developed by Neo4j. Not only does Cypher provide an efficient and scalable solution for querying and manipulating graph data, but it also offers a visual way of matching patterns and relationships, making it intuitive and easy to use.
The application of Cypher in GraphScope Interactive can be categorized into two main areas:
On-the-Fly Read Queries: Users can submit Cypher read queries directly to the engine. These queries are then automatically compiled into a dynamic library for execution, providing immediate results.
Stored Procedures: Users can create a Cypher file with specified parameters denoted as
${param_name}. Using the admin tool, this code can be compiled into a stored procedure and registered within the system. This stored procedure can then be invoked for future use via Cypher’s CALL clause.
The Cypher endpoint is enabled by default and listens on port 7687. You can also turn of the bolt connector or customize the port it by setting properties under compiler.endpoint.bolt_connector. For more detail explanation, please refer to Configuration guide. For instructions on how to connect to the Cypher endpoint, please see GettingStarted.
Limitations¶
GraphScope Interactive now only supports a subset of Cypher read clause, as indicated in supported_cypher. Write and DDL (for defining and modifying schema) functionalities are not currently provided.
Writes are designed to be fulfilled via built-in stored procedures. Currently writes are not supported.
ACID is currently not supported, but it is planned to be supported in the near future.