Ingress: Incrementalize Graph Algorithms¶
Ingress is an automated system for incremental graph processing. It is able to incrementalize batch vertex-centric algorithms into their incremental counterparts as a whole, without the need of redesigned logic or data structures from users. Underlying Ingress is an automated incrementalization framework equipped with four different memoization policies, to support all kinds of vertex-centric computations with optimized memory utilization.
Motivation¶
Most graph systems today are designed to compute over static graphs. When input changes occur, these systems have to recompute the entire algorithm on the new graph, which is costly and time-consuming. This is especially true for graphs with trillions of edges, such as e-commerce graphs that are constantly changing.
To address this issue, incremental graph computation is needed. This involves applying a batch algorithm to compute the result over the original graph, followed by using an incremental algorithm to adjust the old result in response to input changes. Real-world changes are typically small, and there is often an overlap between the computation over the old graph and the recomputation on the new graph. This makes incremental computation more efficient, as it reduces the need for unnecessary recomputation. However, existing incremental graph systems have limitations, such as the need for manual intervention and the use of different memoization policies. This can be a burden for non-expert users.
Design of Ingress¶
Overview¶
In light of these challenges, Ingress is developed, which is an automated vertex-centric system for incremental graph processing. The overall structure of Ingress is shown in the following figure. Given a batch algorithm A, Ingress verifies the characteristics of A and deduces an incremental counterpart ∆A automatically. It selects an appropriate memoization engine to record none or part of run-time intermediate states. Upon receiving graph updates, Ingress executes ∆A to deliver updated results with the help of memoized states.
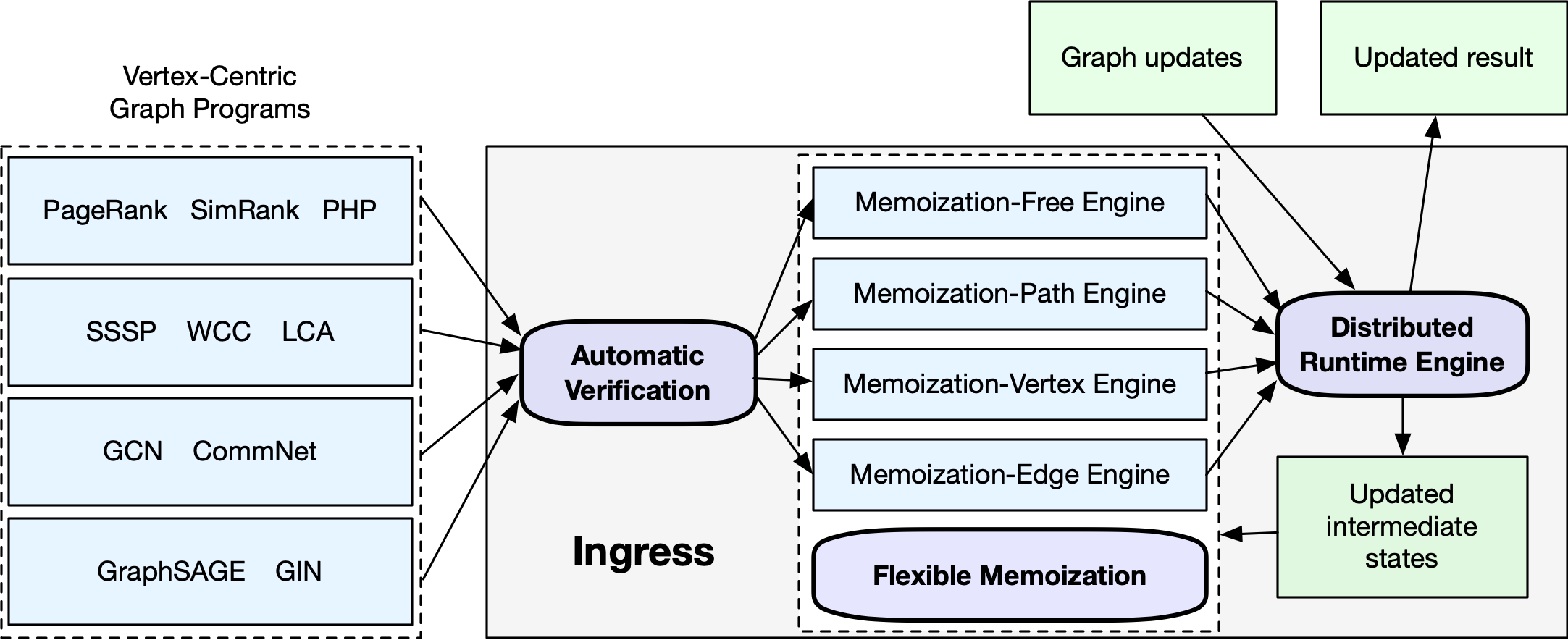
The Ingress architecture.¶
Ingress features the followings that differ from previous systems:
(1) Ingress supports a flexible memoization scheme and can perform the incrementalization, i.e., deducing an incremental counterpart from a batch algorithm, under four different memoization policies.
(2) Ingress incrementalizes generic batch vertex-centric algorithms into their incremental counterparts as a whole. There is no need to manually reshape the data structures or the logic of the batch ones, improving ease-of-use.
(3) Ingress also achieves high performance runtime.
Message-driven Differentiation¶
Ingress’s incremental model for graph processing is based on message-driven differentiation. In a vertex-centric model, the (final) state of each vertex v is decided by the messages that v receives in different rounds of the iterative computation. Due to this property, we can reduce the problem of finding the differences among two runs of a batch vertex-centric algorithm to identifying the changes to messages. Then for incremental computation, after fetching the messages that differ in one round of the runs over original and updated graphs, it suffices to replay the computation on the affected areas that receive such changed messages, for state adjustment. After that, the changes to the messages are readily obtained for the next round and the algorithm can simply perform the above operations until all changed messages are found and processed. This coincides with the idea of change propagation.
Flexible Memoization¶
A simple memoization strategy for detecting invalid and missing messages is to record all the old messages. Then the changed messages can be found by direct comparison between the messages created in the new run and those memoized ones. Although this solution is general enough to incrementalize all vertex-centric algorithms, it usually causes overwhelming memory overheads, especially for algorithms that take a large number of rounds to converge.
Ingress offers a flexible memoization scheme that can perform incrementalization under four different memoization policies:
(1) the memoization-free policy (MF) that records no runtime old messages (e.g., Delta-PageRank, Delta-PHP);
(2) the memoization-path policy (MP) that only records a small part of old messages (e.g., SSSP, CC, SSWP);
(3) the memoization-vertex policy (MV) that tracks the states of the vertices among different steps (e.g., GCN and CommNet);
(4) the memoization-edge policy (ME) that keeps all the old messages (e.g., GraphSAGE,GIN).
Ingress could automatically select the optimal memoization policy for a given batch algorithm. For details on how it decides the optimal memoization policies, please refer to a VLDB paper published in 2021.
Ingress API¶
Ingress follows the well-known vertex-centric model and provides an API to users for writing batch vertex-centric algorithms. In this model, the template types of vertex states and edge properties are denoted by D and W, respectively. Users should set the initial values of the vertex states and messages using the init_v and init_m interfaces, respectively. The aggregation function is implemented using the aggregate interface, which has only two input parameters. However, this can be generalized to support different numbers of input parameters if H is associative.
Although aggregate supports only two input parameters for simplicity, we also provide another interface for function that can take a vector of elements as input. The update function of the vertex-centric model is specified by the update interface, which adjusts vertex states. Additionally, the generate interface in the API corresponds to the propagation function G, which generates messages.
template <class D, class W>
interface IteratorKernel {
virtual void init_m(Vertex v, D m) = 0;
virtual void init_v(Vertex v, D d) = 0;
virtual D aggregate(D m1, D m2) = 0;
virtual D update(D v, D m) = 0;
virtual D generate(D v, D m, W w) = 0;
}
Using this API, the implementation of the batch SSSP algorithm is as below:
class SSSPKernel: public IteratorKernel {
void init_m(Vertex v, double m) { m = DBL_MAX; }
void init_v(Vertex v, double d) {
v.d = ((v.id == source) ? 0 : DBL_MAX);
}
double aggregate(double m1, double m2) { return m1 < m2 ? m1 : m2; }
double update(double v, double m) { return aggregate(v, m); }
double generate(double v, double m, double w) { return v + w; }
}
Distributed Runtime Engine¶
The distributed runtime engine of Ingress is built on top of the fundamental modules of GraphScope. Ingress inherits the graph storage backend and graph partitioning strategies from GraphScope, which ensures a seamless integration between the two systems. In addition, Ingress has several new modules that enhance its functionality. These modules include:
Vertex-centric programming. Ingress extends the block-centric programming model to achieve vertex-centric programming. Specifically, Ingress spawns a new process on each worker to handle the assigned subgraph. It adopts the CSC/CSR optimized graph storage for fast query processing of the underlying graphs. For each vertex, it invokes the user-specified vertex-centric API to perform the aggregate, update, and generate computations. The generated messages are batched and sent out together after processing the whole subgraph in each iteration. Ingress relies on the message passing interface for efficient communication with other workers.
Data maintenance. Ingress launches an initial batch run on the original input graph. It preserves the computation states during the batch iterative computation, guided by the selected memoization policy, e.g., preserving the converged vertex states only as in MF policy or the effective messages with MP policy. After that, Ingress is ready to accept graph updates and execute the deduced incremental algorithms to update the states. The graph updates can include edge insertions and deletions, as well as newly added vertices and deleted vertices. In particular, the changed vertices with no incident edges are encoded in “dummy” edges with one endpoint only. Furthermore, changes to edge proprieties are represented by deletions of old edges and edge insertions with the new properties.
Incremental processing. Ingress starts the incremental computation from those vertices involved in the input graph updates, which are referred to as affected vertices. Using the message deduction techniques, for each of these affected vertices, Ingress will generate the cancellation messages and compensation messages based on the new edge properties and the preserved states. These messages are sent to corresponding neighbors. Only the vertices that receive messages are activated by Ingress to perform the vertex-centric computation, and only the vertices whose states are updated can propagate new messages to their neighbors. This process proceeds until the convergence condition is satisfied.