Last time, we presented an overview of the GAIA engine for scaling Gremlin for large distributed graphs. In contrast to other, existing batch-oriented big graph processing systems, such as Google Pregel, Apache Giraph, GraphLab PowerGraph, and Apache Spark GraphX, GAIA focuses on low-latency graph traversal at scale. Achieving this goal requires a different distributed infrastructure. Today, we continue to explain why with highlighting two unique and key features of GAIA.
We are glad to announce the GraphScope 0.5 release. As the first step towards the ease of deployment in production, this major release includes two new features, namely a persistent graph store to enable a “service mode” for real-time graph computing, and lazy evaluation of GraphScope programs–an execution strategy which delays the execution of a GraphScope program until later when needed for efficiency. In addition, we improve the compatibility with NetworkX.
We highlight the following improvements included in this release:
GraphScope-Store: A persistent store for mutable graphs. Currently, it has supported the following features/functions:
Today, we’re announcing the availability of GraphScope v0.4.0. This release focuses on
the compatibility improvement with NetworkX, with the aim of allowing users to
develop graph applications on large-scale graphs in a distributed environment just
like doing this on a single machine. In addition, this release improves the
experience of standalone deployment.
GAIA extends GraphScope with Gremlin, the industry’s de facto standard property graph query language defined and maintained by the Apache TinkerPop project, which is widely adopted by popular graph database vendors such as Neo4j, OrientDB, JanusGraph, Microsoft Cosmos DB, and Amazon Neptune. GAIA is the first open-source implementation of Gremlin in a distributed or big-data environment in the industry.
GraphScope v0.3.0 is released as scheduled. This release includes new features and major updates for frontend APIs for graph manipulation, integration with other systems as well as code optimization for some operators. Another direction we are working on is to ease the deployment of GraphScope with/without Kubernetes.
To explore underlying insights hidden in graph data, many graph analytics algorithms, e.g., PageRank and single source shortest paths (the Dijkstra’s algorithm), have been designed to solve different problems.
Today we released GraphScope 0.2.0. With this release, we are happy to introduce GraphScope Playground, a hosted JupyterLab with GraphScope ready out-of-the-box. Now you can get started with GraphScope straight away in your browser without any hassle for setting it up.
The GraphScope team is pleased to announce the 0.2.0 release after two-months development.
The 0.2.0 release is focused on better getting started experience for end-users and we have
make a lot of improvements since the last minor release. We have improved our documentation
a lot, and made the kubernetes integration work for more settings. We have also brought the
support for various I/O to make GraphScope suitable for more production environments.
 Last time, we presented an overview of the GAIA engine for scaling Gremlin for large distributed graphs. In contrast to other, existing batch-oriented big graph processing systems, such as Google Pregel, Apache Giraph, GraphLab PowerGraph, and Apache Spark GraphX, GAIA focuses on low-latency graph traversal at scale. Achieving this goal requires a different distributed infrastructure. Today, we continue to explain why with highlighting two unique and key features of GAIA.
Last time, we presented an overview of the GAIA engine for scaling Gremlin for large distributed graphs. In contrast to other, existing batch-oriented big graph processing systems, such as Google Pregel, Apache Giraph, GraphLab PowerGraph, and Apache Spark GraphX, GAIA focuses on low-latency graph traversal at scale. Achieving this goal requires a different distributed infrastructure. Today, we continue to explain why with highlighting two unique and key features of GAIA. We are glad to announce the GraphScope 0.5 release. As the first step towards the ease of deployment in production, this major release includes two new features, namely a persistent graph store to enable a “service mode” for real-time graph computing, and lazy evaluation of GraphScope programs–an execution strategy which delays the execution of a GraphScope program until later when needed for efficiency. In addition, we improve the compatibility with NetworkX.
We highlight the following improvements included in this release:
We are glad to announce the GraphScope 0.5 release. As the first step towards the ease of deployment in production, this major release includes two new features, namely a persistent graph store to enable a “service mode” for real-time graph computing, and lazy evaluation of GraphScope programs–an execution strategy which delays the execution of a GraphScope program until later when needed for efficiency. In addition, we improve the compatibility with NetworkX.
We highlight the following improvements included in this release:
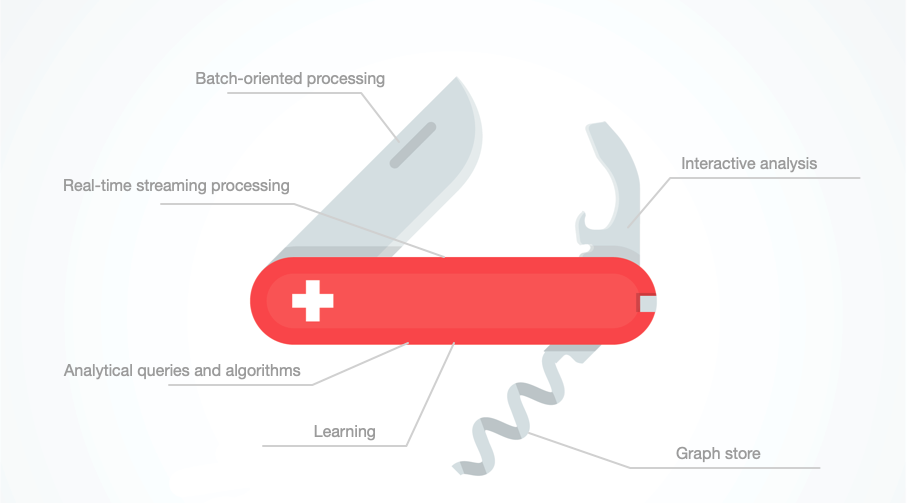 In this post, we will present a high-level road-map of the GraphScope project with highlighting new exciting features coming in the v0.5 release.
In this post, we will present a high-level road-map of the GraphScope project with highlighting new exciting features coming in the v0.5 release.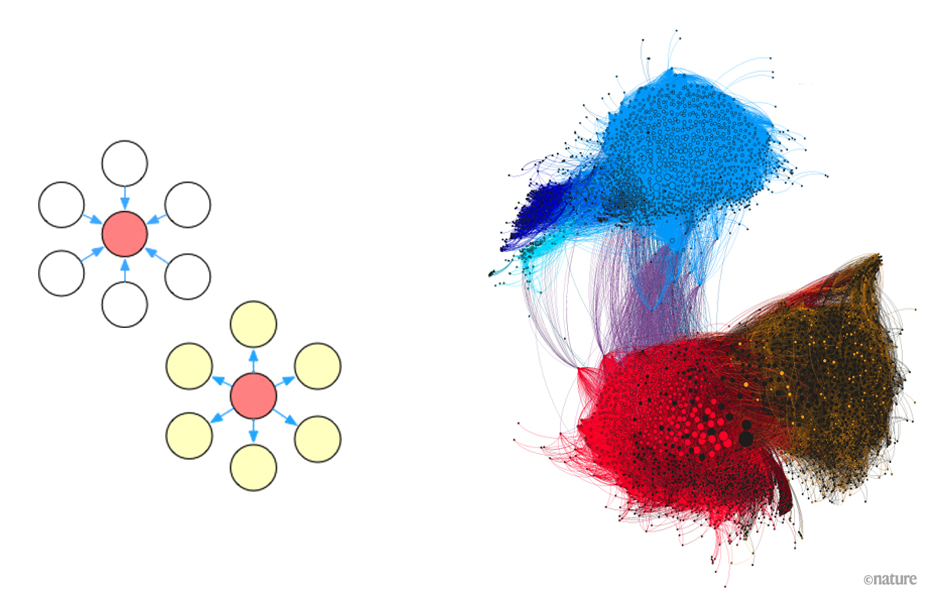 To explore underlying insights hidden in graph data, many graph analytics algorithms, e.g., PageRank and single source shortest paths (the Dijkstra’s algorithm), have been designed to solve different problems.
To explore underlying insights hidden in graph data, many graph analytics algorithms, e.g., PageRank and single source shortest paths (the Dijkstra’s algorithm), have been designed to solve different problems.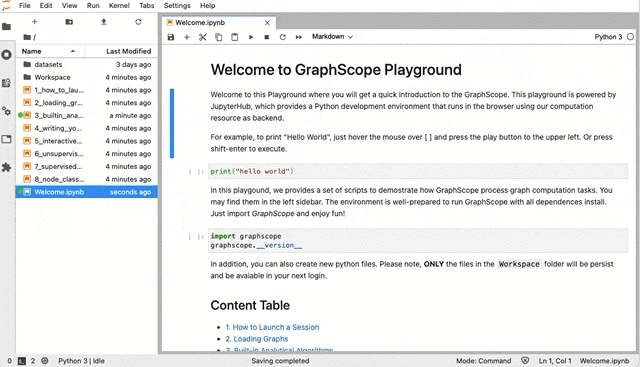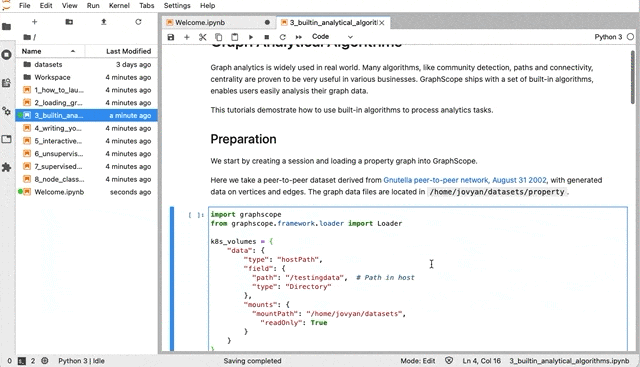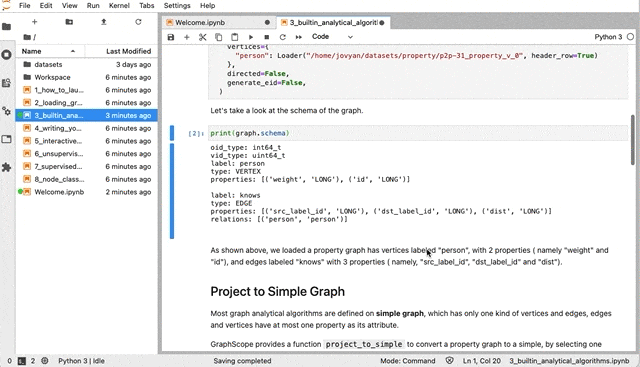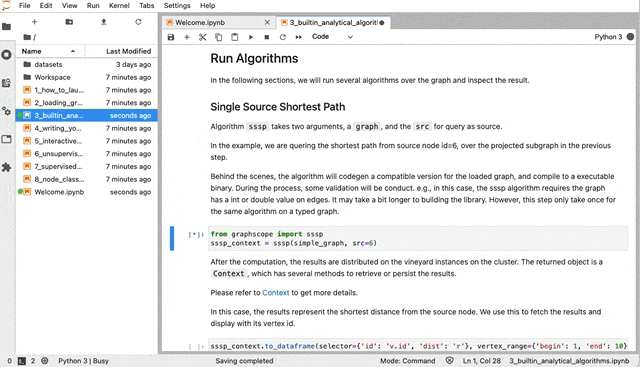 Today we released
Today we released  The source code of GraphScope is released today!
The source code of GraphScope is released today!